О чем материал
Разбираемся, как выстроить масштабируемый MDR-сервис за счет централизованного управления и повышения качества детектирующего контента в SIEM
Последний год слово «масштабируемость» чаще других звучало в операционном блоке PT X. Но это не очередной маркетинговый штамп, а необходимость, без которой невозможно построить тиражируемый MDR-сервис.
Одним из наших ключевых векторов была работа с контентом Knowledge Base в SIEM. Кратное увеличение числа заказчиков, подключение большого количества EDR-агентов и внедрение дополнительных источников повлекли за собой экспоненциальный рост корреляционных событий. Это неизбежно приводит к двум фундаментальным проблемам:
- Перегрузка аналитиков SOC: растет утомляемость смен, увеличивается время верификации, снижается качество расследований и повышается риск упустить атаку на фоне шума.
- Расхождение версий пакетов экспертизы между заказчиками: появляются локальные изменения и пользовательские правила, которые необходимо централизованно поддерживать и переиспользовать на других площадках.
В итоге детектирующий контент может превратиться в зоопарк точечных реактивных правил. Такой подход несовместим с масштабируемой моделью MDR: снижается управляемость, а вместе с ней — и качество сервиса.
В ответ на эти вызовы мы сформулировали конкретные цели:
- Снизить долю ложноположительных и легитимных подозрений на инциденты без потери чувствительности детектирования.
- Унифицировать контент SIEM, который мы поставляем в инфраструктуры на этапе подготовки к мониторингу.
- Обеспечить централизованное управление контентом из единого источника с прозрачным контролем версий и изменений.
Реализация
Люди
В классической модели SOC экспертность распределена по всей линии аналитиков: каждый знает определенные правила, исключения и нюансы инфраструктуры. При росте числа заказчиков модель разрушается: знания фрагментируются, возникают расхождения в интерпретации срабатываний, а контент деградирует. Поддерживать все это через статическую Knowledge Base неэффективно.
Соответственно, первым делом мы сформировали отдельную группу аналитиков, ответственных именно за экспертизу и развитие детектирующего контента. Это организационное решение закрыло одну из системных проблем масштабируемого MDR — фрагментацию экспертных знаний.
Также мы выделили команду специалистов, которая отвечает за жизненный цикл MDR-контента. По сути, это переход от эксплуатационной парадигмы к продуктовой: в ней детектирующий контент рассматривается как управляемый актив.
Процессы
Следующей задачей стало проектирование регламентированного и воспроизводимого процесса снижения False Positive — как на этапе подготовки заказчика к мониторингу, так и в рамках регулярного анализа за отчетные периоды. Здесь важно понимать, что FP не всегда ошибка детектирующей логики, в большинстве случаев это:
- нетипичные, но легитимные бизнес-процессы;
- высокая вариативность поведения пользователей и сервисных аккаунтов;
- абсолютно легитимные действия с точки зрения архитектуры заказчика.
Для нас принципиально важно было вывести работу с ложными срабатываниями из разряда реактивных действий (например, «перекрыть спам») в формализованный процесс с четкими этапами, критериями и зонами ответственности. Ведь задача аналитиков — верификация, расследование и реагирование на подтвержденные инциденты. Если тратить их ресурс на обработку потока легитимных событий, которые ошибочно классифицируются как инциденты, неизбежно увеличится время на верификацию и реагирование. В худшем случае это приведет к пропуску реальной атаки…
Отметим, что обработку сгенерированных подозрений на инциденты нельзя начинать с ходу. Любая подключенная к мониторингу инфраструктура требует фильтрации и тюнинга детектирующих механизмов. Поэтому работа с FP начинается еще на этапе онбординга — задолго до первой смены SOC.
Онбординг в рамках Knowledge Base — это этап формирования базовой модели нормального поведения инфраструктуры, на которую затем накладывается экспертиза продукта. Он включает:
- изучение архитектуры (AD, сегментация, периметр, бизнес-системы, состав и тип сервисов);
- выявление привилегированных и технических учетных записей;
- анализ типовых административных операций и особенностей инфраструктуры.
Цель онбординга в рамках работы с контентом — настроить экспертизу так, чтобы подозрительное поведение действительно отличалось от нормы, а не от абстрактной эталонной модели.
Ключевые инструменты:
- Профилирование контента. Настройка параметров, чувствительности, исключений и контекстных атрибутов без форка основной логики правила корреляции (на основе табличных списков).
- Создание белых списков (Whitelisting). Исключение из анализа событий, связанных с известными легитимными процессами. Это самый распространенный метод снижения FP и повышения производительности SIEM. Применяется строго контролируемо и в нескольких форматах: по точному значению, регулярным выражениям, подсетям и системе меток (инструкция).
- Корректировка порогов модуля BAD (Behavioral Anomaly Detection). С помощью ML модуль анализирует поведение пользователей, сетевой трафик, использование ресурсов и процессы в инфраструктуре. BAD формирует эталонные поведенческие шаблоны, при нарушении которых проводится оценка риска (на высоких значениях модуль сигнализирует о подозрительной активности). Корректировка пороговых значений осуществляется в табличном списке BAD_Risk_Score_Thresholds.
- Изменение логики правил с учетом инфраструктурных особенностей. В ряде случаев FP нельзя исключить доступными параметрами, а значит, требуется корректировка самой логики правила:
- добавление дополнительных условий, уточнение контекста;
- изменение последовательности событий или периода сбора событий в корреляцию;
- корректировка ключевых полей для агрегации корреляционных событий.
- Понижение типа корреляционного события. Некоторые корреляционные правила предназначены для обнаружения конкретных действий (запуски программ, сетевое взаимодействие и т. д.). В процессе внедрения EDR-агентов заказчики часто отмечают подобную активность как легитимную. Аналитик SOC действительно не должен видеть такие сработки в потоке подозрений на инцидент, но при необходимости должен иметь возможность обратиться к ним в процессе расследования, чтобы получить полный контекст происходящего в инфраструктуре. Здесь на помощь приходит табличный список correlation_type_overriding, который осуществляет контроль типа правила на последнем этапе формирования корреляционного события. Так, тип «event» — это событие, которое не требует внимания в данный момент, но может пригодиться при ретроспективном анализе и расследовании атаки.
- Осознанное отключение правил. В отдельных случаях анализ показывает, что правило не достигает приемлемого уровня точности, неприменимо к архитектуре заказчика или же не несет практической ценности. Тогда оно попросту отключается, и это не дурной тон, а, наоборот, показатель зрелости процесса. Детектирующий контент должен быть эффективным, а не просто «включенным по умолчанию из коробки».
Но на онбординге работа с FP не заканчивается, а переходит в режим непрерывного цикла улучшений и расширения набора инструментов.
Технологии
PT CMC (Positive Technologies Central Management Console)
Для централизованного управления контентом мы использовали PT CMC — систему управления тенантами MaxPatrol SIEM, развернутых в рамках одной или нескольких организаций. Она позволяет:
- Управлять тенантами, просматривать приложения и роли пользователей.
- Создавать пакеты экспертизы из установочных наборов Knowledge Base.
- Доставлять пакеты экспертизы на выбранные тенанты и отслеживать статус доставки.
- Контролировать актуальность объектов, которые входят в пакеты экспертизы, и создавать новые версии пакетов с учетом изменений.
Соответственно, использование PT CMC помогло нам решить обозначенные ранее проблемы:
- Расхождение версий пакетов экспертизы между заказчиками.
- Централизованная поддержка и переиспользование пользовательских правил.
- Доставка и установка унифицированного контента на всех этапах мониторинга.
Content Inquisitor
Далее мы занялись автоматизацией контроля качества контента. При росте числа заказчиков ручной анализ в рамках отчетных периодов перестал быть масштабируемым: данные разрознены, динамика неочевидна, а реакция на деградацию запаздывает. Для решения проблемы мы разработали Content Inquisitor — сервис операционного мониторинга качества детектирующего контента, реализованный на базе нашего решения Anthill IRP. Задача Content Inquisitor — не просто считывать количество сработок, а выявлять деградацию точности правил во времени и инициировать корректирующие действия без участия человека на этапе первичного анализа.
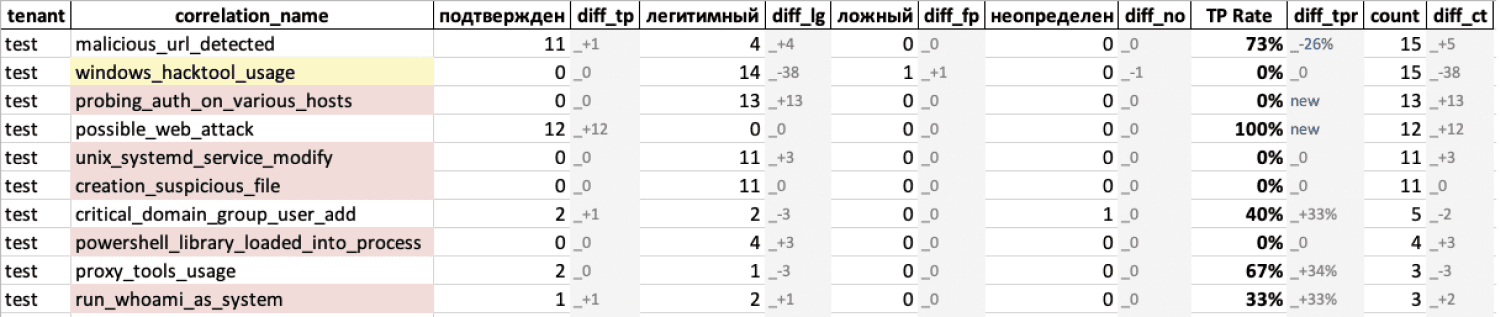
Наш сервис реализует простой, но эффективный принцип: качество обнаружения нужно контролировать постоянно, а не решать разом гору накопившихся проблем. Content Inquisitor проводит сравнительный анализ двух последовательных отчетных периодов и выявляет правила, демонстрирующие рост FP. Алгоритм его работы выглядит так:
- Сбор данных
Система автоматически выгружает обработанные инциденты за 14 дней и разбивает их на два равных периода. При этом используются только верифицированные аналитиками инциденты с финальным вердиктом.
- Агрегация
Далее выполняется агрегация по нескольким атрибутам:
- название правила корреляции;
- площадка (тенант);
- тип вердикта (подтвержден/ложный/легитимный);
- общее количество алертов.
Таким образом формируется многомерная матрица качества детектирования.
- Сравнение периодов
Система вычисляет абсолютный прирост сработок по типам вердикта и изменение доли FP между периодами. Отметим, что анализируется не только рост количества FP, но и ухудшение процента точности правила. Рост инфраструктуры может сам по себе увеличить количество корреляционных событий, и это нормально. Проблема возникает, когда растет процент ложных срабатываний.
- Расчет ключевых метрик
Для каждого правила и площадки рассчитываются:
- True Positive Rate (TPR) = True Positive / общее число алертов;
- динамика TPR относительно предыдущего периода.
Эти метрики позволяют отличать шумные правила от часто срабатывающих, но с приемлемым TPR.
- Сортировка и приоритизация
Правила сортируются по общему количеству сработок и уровню деградации точности обнаружения (TPR). Предусмотрены механизм исключений, управляемый уровень TPR и возможность изменять количество передаваемых на доработку правил за отчетный период (по умолчанию TPR равен 40% — это критичный уровень, при котором правило начинает создавать непропорциональную нагрузку на SOC).
- Автоматическая генерация задач
Content Inquisitor интегрирован с корпоративным планировщиком задач. После формирования перечня правил на доработку:
- автоматически создаются задачи на ответственных;
- прикладываются агрегированные метрики и динамика;
- фиксируются площадка, правило корреляции и временной период.
Таким образом, процесс перестает быть реактивным («аналитики пожаловались») и становится проактивным, а также метрико-ориентированным. В результате управление качеством детектирующего контента строится на основе объективных показателей, а не на субъективной обратной связи. При этом сохраняется механизм оперативной эскалации проблем детектирующей логики: аналитик может в моменте зафиксировать некорректность или деградацию правила. Такие обращения регистрируются в корпоративном планировщике наравне с задачами, которые автоматически создаются по результатам работы Content Inquisitor. Это обеспечивает единую базу для учета, приоритизации и контроля исполнения тикетов.
Практические результаты использования Content Inquisitor:
- автоматизированная подготовка отчетов;
- раннее выявление деградации правил;
- быстрое исправление проблем;
- принятие решений на основе данных, а не догадкок.
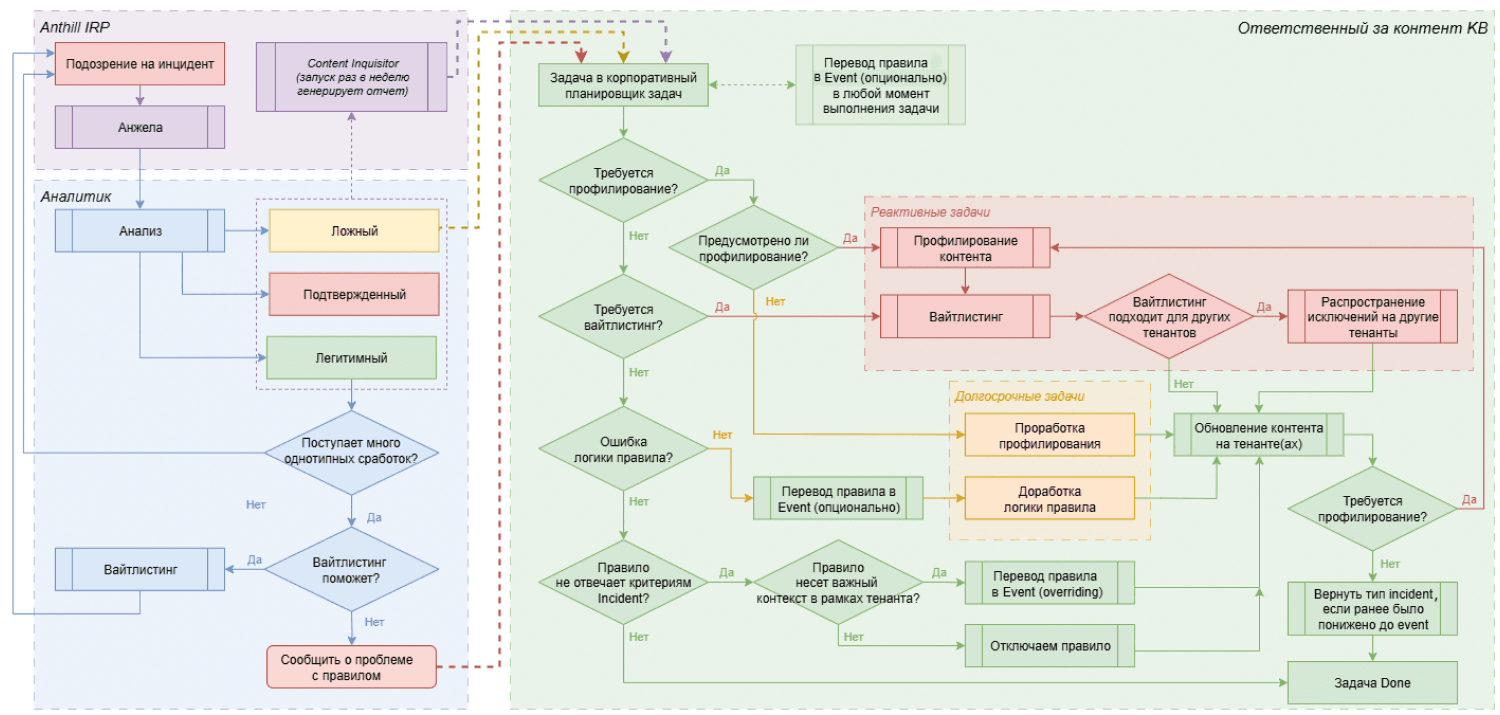
Кодовое слово «Анжела»
Чтобы еще больше снизить нагрузку на SOC, мы реализовали механизм автоматизированной обработки однотипных сработок. Он применяется в случаях, когда предварительная настройка пакетов экспертизы и исключений завершена, дальнейшее использование этих инструментов нецелесообразно, а уровень FP остается высоким. Кроме того, эта функциональность частично нивелирует эффект шумящих правил.
Для решения задачи мы разработали ML-агент «Анжела», который интегрирован в Anthill IRP и обрабатывает инциденты вместе с аналитиками SOC. Агент использует ML-модели, обученные на исторических данных об инцидентах, и выполняет автоматическую верификацию типовых кейсов по принципу поведенческого и контекстного сходства. «Анжела» принимает в обработку инциденты низкой и средней критичности. Результаты ее работы, включая классификацию и принятые решения, в обязательном порядке проходят последующий контроль и ревью со стороны аналитиков. Таким образом мы обеспечиваем управляемый уровень автоматизации без потери качества расследования.
Результаты
Вместо тысячи слов покажем цифры ;)
| KPI | Базовый уровень (II–III кв. 2025) | Текущий уровень (IV кв. 2025 – I кв. 2026) | Δ от базового уровня |
| True Positive Rate (среднее по всем клиентам PT X) | 6,63% | 16,10% | ↑ 142,78% |
| Время доставки и установки нового контента | 16 ч | 30 мин | ↓ 97 % |
| Время онбординга (в рамках контента) | 7 дней | 3 дня | ↓ 57 % |
| Скорость обнаружения деградации правила | 14 дней | 7 дней | ↓ 50 % |
За полгода нам удалось перевести процесс работы с контентом SIEM из фрагментированной, реактивной модели в управляемую и автоматизированную. Осталось автоматизировать CI/CD, разработать механизм доставки отдельных строк табличных списков SIEM и продолжать совершенствовать разработанные инструменты автоматизации и ML. Это позволит нам подготовить MDR сервис к существенному росту клиентской базы без деградации качества.




