О чем материал
Рассказываем, как разные методы кластеризации помогают решать актуальные ИБ-задачи.
Объемы данных, которые нужно обрабатывать для обеспечения защиты компании, продолжают расти. Логи, сетевой трафик, отчеты об инцидентах и другие источники генерируют колоссальные массивы событий, среди которых нужно выявлять аномалии и группировать схожие сущности. Один из способов решения подобных задач — кластеризация. Это метод машинного обучения, который позволяет группировать объекты по схожести без заранее заданных классов.
Кластеризация командлайнов
Для решения задачи анонимизации командлайнов Unix и Windows нам нужно было собрать как можно больше уникальных строк, содержащих различные секреты: пароли, токены доступа, API-ключи и т. д.

Первоначально мы производили отбор следующим образом:
- Загрузили командлайны из потока событий в отдельную БД.
- Выполнили SELECT-запрос.
- Выбрали понравившийся командлайн.
- Добавили в запрос условие, чтобы подобные командлайны больше не попадались.
- Повторили шаги 2–4 для дальнейшего отбора.

Этот отбор дал нам первоначальные N командлайнов, но постоянно собирать данные таким образом нельзя — слишком медленно. Значительно ускорить и упростить процесс удалось с помощью кластеризации на основе алгоритма MinHash.
MinHash — это вероятностный алгоритм, который применяется для оценки коэффициента Жаккара (меры схожести двух множеств). Коэффициент Жаккара определяется следующим образом:
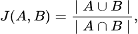
где:
- ∣A∪B∣ — количество совпадающих элементов во множествах A и B.
- ∣A∩B∣ — общее количество элементов в объединении множеств A и B.

После преобразования командлайнов в MinHash мы можем рассчитать матрицу попарных расстояний и применить один из алгоритмов кластеризации (см. рис. 3). В этой задаче наилучшие результаты показал наивный алгоритм:
- Для каждого командлайна выбираем похожие (схожесть с которыми превышает некоторый порог) — получаем кластер.
- Повторяем процесс, пока командлайнов не останется.
Мы применили аналогичный подход для логов джоб GitLab CI, в которых часто встречаются секреты (пароли и токены доступа). GitLab заменяет подобные секреты на строку [MASKED], что упрощает их поиск. Например:
$echo DB_PASSWORD is $DB_PASSWORD
DB_PASSWORD is [MASKED]
$echo SECRET_KEY is $SECRET_KEY
SECRET_KEY is /builds/tmp/SECRET_KEY
Мы получили выгрузку логов за несколько лет, содержащую миллионы записей отдельных джоб. На первом этапе провели фильтрацию: если строка не содержала [MASKED], значит, в ней не было секретов. Затем перешли ко второму этапу — предобработке данных, которая включала:
- удаление мусорных символов (NBSP, ANSI escape sequences, переносы строк, табуляции и т. п.);
- удаление уровня логирования (INFO, ERROR и т. п.);
- удаление управляющих последовательностей ANSI, которые применяются для окраски текста в терминале.
К очищенным логам мы применили кластеризацию на основе MinHash — это позволило расширить обучающую и тестовую выборки.
Кластеризация событий в Xpertise
Нормализация данных — ключевой элемент работы SIEM-систем. Информация в SIEM поступает из разных источников: журналы событий (лог-файлы) от сетевых устройств, серверов, приложений, антивирусных программ и др. Такие данные могут отличаться по формату и структуре, содержать различные поля и метаданные. Например, журналы событий от устройств одного типа могут фиксировать информацию с разной логикой формирования сообщений. В процессе нормализации данные из источников приводятся к единой схеме, которую определяет SIEM (в системе заполняются соответствующие поля).
Перед созданием контента важно разделить логи от источников на группы схожих сообщений. Логи могут быть представлены следующими MIME-типами: text/plain; application/json; text/csv; application/x-pt-eventlog.
- Для application/x-pt-eventlog кластеризация тривиальна и сводится к группировке по полю EventID.
- В application/json и text/csv каждый лог — это словарь с произвольной структурой, из которого предварительно необходимо извлечь информативные поля.
- Для text/plain мы сразу переходим на этап препроцессинга.
Парсинг структурированных логов
Первый шаг — преобразование каждого лога в плоскую структуру, например:
| Исходный лог | Плоский лог |
|---|---|
|
|
При получении плоских логов также выполняем следующие шаги:
- Преобразование ключей в редуцированные ключи, то есть без целочисленных частей. Например, ключ ('key5', 0, 'key6') будет редуцирован в ключ ('key5', 'key6').
- Сбор уникальных значений для каждого редуцированного ключа.
- Определение возможных типов данных для каждого редуцированного ключа с помощью набора регулярных выражений. Поддерживаются следующие типы данных: NUMBER, BOOL, NONE, DATETIME, DURATION, SITE, HOSTNAME, IPv4, IPv6, MACADDR, LINUX_PATH, UUID. Если для ключа не найдены возможные типы данных, мы подразумеваем, что он содержит только текст.

Затем отбираем поля на основе уникальных значений и возможных типов данных:
- Определяем первое множество признаков — редуцированные ключи, имеющие уникальные значения только с типом TEXT.
- Определяем второе множество признаков — редуцированные ключи, имеющие больше одного уникального значения.
- Находим пересечение первого и второго множеств. Если оно пустое, объединяем их. Полученное множество называем selected.
- Проводим whitelisting редуцированных ключей на основе предопределенного списка интересующих нас сущностей (например, action, entity и т. п.). Если ключ содержит хотя бы одну из них, считаем его информативным. Полученное множество называем whitelisted.
- С помощью LLM проводим отбор ключей, используя описание интересующих нас сущностей и технику few-shot prompting. Полученное множество называем llm_fields.
- Если llm_fields не пустое, объединяем его с whitelisted. В противном случае объединяем selected с whitelisted.
- Проводим финальную фильтрацию: исключаем поля, которые могут содержать имена пользователей. Для этого проверяем ключи на наличие строк username, fullname и аналогичных маркеров.
После этого из каждого плоского лога собираем значения, соответствующие отобранным полям, — с учетом преобразования редуцированных ключей в оригинальные. Значения объединяются в одну строку, которая отправляется на этап препроцессинга.
Препроцессинг
Препроцессинг влияет на качество дальнейшей кластеризации. Он включает следующие этапы:
- Удаление символов переноса строки.
- Удаление параметров — подстрок вида “key=value”.
- Удаление сущностей с типами данных NUMBER, BOOL, NONE, DATETIME, DURATION, SITE, HOSTNAME, IPv4, IPv6, MACADDR, LINUX_PATH, UUID.
- Удаление токенов, начинающихся или целиком состоящих из пунктуации.
- Удаление токенов, разделенных косой чертой.
- Удаление токенов длиной меньше четырех символов.
- Удаление уровней логирования.
- Удаление пустых параметров — подстрок вида “key=”.
- Удаление оставшейся пунктуации.
- Удаление UTF BOM.
- Лемматизация: для русского языка используем pymorphy2, для английского — spacy.
- Дедупликация на уровне токенов.
- Дополнительное удаление токенов длиной меньше четырех символов.
- Замена подряд идущих пробелов на один.
Кластеризация
В качестве метрики схожести мы использовали token_set_ratio из библиотеки rapidfuzz. Эта функция сравнивает две строки — анализирует их уникальные и общие слова, рассчитывая расстояние Индела. На основе этих данных рассчитываем матрицу схожести, а для получения матрицы расстояния применяем формулу «1 – sim».
Далее используем алгоритм HDBSCAN c минимальным размером кластера 2 и параметром epsilon = 0,05 (он показал лучшие результаты, чем DBSCAN). Алгоритмы по типу KMeans нам не подходят, так как они требуют заранее задать число кластеров, а перебирать значения мы не можем из-за ограничений по скорости.
Отмечу, что HDBSCAN может назначить некоторым образцам кластер -1 (признать их выбросами). Для таких случаев мы выполняем перекластеризацию тем же алгоритмом.

Кластеризация сработок в BAD
В MaxPatrol SIEM есть ML-модуль поведенческого анализа Behavioral Anomaly Detection (BAD), который работает как система second opinion. Он собирает и анализирует данные о событиях, пользователях и процессах, оценивает их и присваивает им определенный уровень риска.
На данный момент BAD генерирует большое количество схожих активностей: аномалии повторяются, но на разных признаках. Чтобы снизить когнитивную нагрузку аналитика SIEM, можно уменьшать вес схожим сработкам. Обнаружить их нам поможет кластеризация с использованием MinHash.
У каждой сработки BAD есть поле triggered_models, которое содержит информацию об атаке:
{
"wm1_seen-chain_alg_on_p_w": "[\"anomaly_detect\", [\"process1.exe (file creator: is executor) ← process2.exe ← process3.exe ← process4.exe ← process5.exe ← process5.exe ← system\"]]",
"m1_chains-anomaly_alg_on_p_w": "[\"text\", [\"process1.exe<-process2.exe | process1.exe<-process3.exe | process1.exe<-process4.exe | process1.exe<-process5.exe | process1.exe<-process5.exe | process1.exe<-system\"]]",
"m7_dangerous-chain_ml_off_p_w": "[\"text\", [\"process1.exe (file creator: is executor) ← process2.exe ← process3.exe ← process4.exe ← process5.exe ← process5.exe ← system\"]]",
"m13_local-net-activity_kv_on_p_w": "[\"new_key\", [\"process1.exe__example1.host.ru\", \"\"]]",
"m49_dns-resolve_kv_on_p_w": "[\"new_key\", [\"c:\\\\windows\\\\process1.exe\", \"example2.host.ru__1.2.3.4\"]]",
"m57_file-creation_kv_on_p_w": "[\"new_key\", [\"example1.host.ru_c:\\\\windows\\\\process1.exe\", \"c:\\\\process6.exe\"]]",
"m58_registry-object-create_kv_on_p_w": "[\"new_key\", [\"example1.host.ru_c:\\\\windows\\\\process1.exe\", \"\\\\registry\\\\machine\\\\system\\\\currentcontrolset\\\\services\\\\tcpip\\\\\"]]",
"m15_pipe_connect_kv_on_p_w": "[\"new_key\", [\"process1.exe\", \"lsass\"]]",
"m74_meta-process_kv_on_p_w": "[\"new_key\", [\"Description:process6.exe | Product:Some Product | Company:Some Corporation\", \"process1.exe\"]]",
"m41_hostname-login_kv_on_j_w": "[\"new_key\", [\"example1.host.ru*process1.exe\", \"example2.host.ru\"]]",
"m9_cmdline-anomaly_alg_on_p_w": "[\"anomaly_0_detect\", [\"system\", \"stones\", \"\\\"C:\\\\windows\\\\process1.exe\\\" /autoupgrade /randomize /fromservicing\"]]",
"m4_port-anomaly_kv_on_j_w": "[\"new_key\", [\"process1.exe\", \"443\"]]"
}
Вычислить хеш одной сработки можно по алгоритму:
- Для каждого значения в метаинформации сработавшей модели выполняем предобработку: удаляем UUID, ID, пунктуацию, заменяем идущие подряд пробелы на один.
- Обновляем MinHash полученными значениями.
- Повторяем шаги 1 и 2 для каждой модели в сработке.
Далее вычисляем коэффициент Жаккара между новой и всеми предыдущими сработками в заданном временном окне. Посчитав пары, где оценка схожести превышает заданный порог, можно снизить вес новой сработки, например, разделив его на количество похожих сработок с некоторым коэффициентом k:
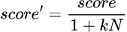
Соответственно, меняя коэффициент k, можно контролировать, как быстро будет снижаться вес сработки (см. рис. 6).

Поиск похожих инцидентов
Для ускорения реагирования и упрощения обучения сотрудников SOC мы реализовали метод, позволяющий находить похожие инциденты.
Каждый инцидент состоит из N событий: для определения похожих сущностей нужно сделать шаг назад и научиться вычислять схожесть событий в MaxPatrol SIEM.

Каждое событие в MaxPatrol SIEM состоит из более чем 200 полей, среди которых можно выделить следующие группы:
- поля корреляционного события;
- поля категоризации событий;
- адресные поля источника события;
- поля, описывающие источник события;
- адресные поля получателя;
- параметры взаимодействия;
- поля, описывающие инцидент;
- поля, описывающие субъект при взаимодействии;
- поля, описывающие объект при взаимодействии;
- информационные поля;
- сервисные поля.
Введем ряд критериев схожести двух событий.
- Схожесть по alert.context и alert.key

Поля alert.context и alert.key содержат наиболее полезную информацию. У них произвольный формат, поэтому в качестве меры схожести мы выбрали нормализованное расстояние Индела. Оно отражает минимальное количество вставок и удалений, необходимых для преобразования одной последовательности в другую. Нормализация позволяет сдвинуть значения расстояния в отрезок от 0 до 1.
- Схожесть по полям категоризации (category.generic, category.high, category.low)

Поле category.generic содержит обобщенную информацию и не несет ценности для решения нашей задачи — в отличие от category.high и category.low. Для вычисления схожести по этим полям используем косинусное расстояние на эмбеддингах от модели multilingual-e5-large. Однако согласно документации у этой модели есть особенность:
3. Why does the cosine similarity scores distribute around 0.7 to 1.0?
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
Для сдвига диапазона в отрезок от 0 до 1 итоговые расстояния масштабируем по следующей формуле:
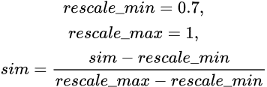
Набор возможных значений полей категоризации относительно постоянен, а новые значения добавляются редко. Это позволяет использовать любые модели (даже самые тяжелые) и заранее рассчитать схожесть.
- Схожесть по имени корреляции
Схожесть по полю correlation_name вычисляем тем же способом, что и для полей категоризации: используем косинусное расстояние на эмбеддингах от модели multilingual-e5-large.
- Схожесть по описанию корреляции
Описание корреляции заполняется по шаблону (см. рис. 10).

У разных, но близких по своей сути корреляций шаблоны похожи или даже совпадают, поэтому поле description можно использовать как один из компонентов схожести. При этом для оценки схожести шаблонов лучше применять нечеткое сравнение строк, а не семантическую схожесть по эмбеддингам. Поскольку шаблоны постоянны, а новые добавляются редко, их схожесть можно рассчитать заранее.
Отмечу два момента:
- Для описаний мы выполнили предобработку по следующему алгоритму:
- удаление placeholder'ов для значений полей;
- удаление datafield'ов;
- удаление пунктуации;
- удаление чисел;
- схлопывание нескольких идущих подряд пробелов в один;
- приведение к нижнему регистру.
- У корреляций может быть несколько описаний. Итоговая схожесть вычисляется как максимальная среди попарных сравнений.
- Схожесть по значениям полей
Схема полей SIEM известна и постоянна, поэтому схожесть по событиям можно вычислить следующим образом:
- Собираем заполненные поля для текущего и закрытого инцидентов — получаем total_fields.
- Берем только те поля, которые есть и в текущем, и в закрытом инциденте, — получаем intersected_fields.
- Считаем число полей, значения которых пересекаются у обоих инцидентов, — получаем overlapping_fields.
Итоговую схожесть (от 0 до 1) рассчитываем по формуле:

Отмечу, что в расчете схожести по значениям полей участвуют не все поля. Например, исключены сервисные и информационные поля, поля, для которых схожесть вычисляется отдельно, и т. д.
Итоговая схожесть событий
Вычислить итоговую схожесть двух событий можно по формуле взвешенного среднего:
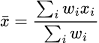
Задание весов для каждого критерия позволяет легко управлять расчетом и отключать ненужные в данный момент компоненты.
Схожесть инцидентов
Подход к вычислению схожести двух событий можно обобщить и на инциденты, поскольку каждый инцидент содержит от одного до N событий. Мы экспериментировали с тремя методами.
Aggregated pairwise — самый простой и понятный способ вычисления схожести двух инцидентов:
- Рассчитываем матрицу попарных расстояний между событиями двух инцидентов.
- Вычисляем некоторую агрегационную функцию над матрицей расстояния: min, max, mean или median.
- Значение агрегационной функции и есть итоговая схожесть.
Если мы добавим к вычислению схожести точный учет каждого события, то получим второй метод — Local top-k. Для каждого события в целевом инциденте:
- Вычисляем схожесть между целевым и всеми событиями текущего инцидента, сохраняя только те, которые превышают порог.
- Вычисляем среднее от собранных значений схожестей.
Наконец, третий метод — Global top-k:
- Вычисляем попарные расстояния между событиями двух инцидентов, отбрасываем значения ниже порога.
- Берем top-k схожестей.
- Итоговая схожесть — их среднее значение.
Отмечу, что метод Aggregated pairwise занижает оценки даже для действительно похожих инцидентов, поэтому мы от него отказались. Local top-k и Global top-k показывают схожие результаты — обе вариации останутся в итоговом решении. Окончательный выбор сделаем на основе фидбэка от SOC ;)



