О чем материал
Рассказываем о применении ML-моделей для поиска и классификации чувствительных данных в PT Data Security.
В прошлом году мы представили MVP платформы для защиты данных PT Data Security. На тот момент наш продукт использовал для поиска и классификации чувствительных данных регулярные выражения и формальную экспертизу. Это стандарт индустрии, который применяется в IBM Guardium, Oracle Data Safe и других решениях. Тем не менее у этого подхода есть недостатки: качество обнаружения данных напрямую зависит от культуры их хранения. Например, проблемы могут вызвать неинформативные названия колонок (col1, value, field123), шумы или пропуски, сокращенные записи, опечатки и т. д. Чтобы усилить экспертизу продукта: увеличить число определяемых сущностей (классов данных) и сократить количество ложных срабатываний, — мы решили внедрить в PT Data Security алгоритмы ML.
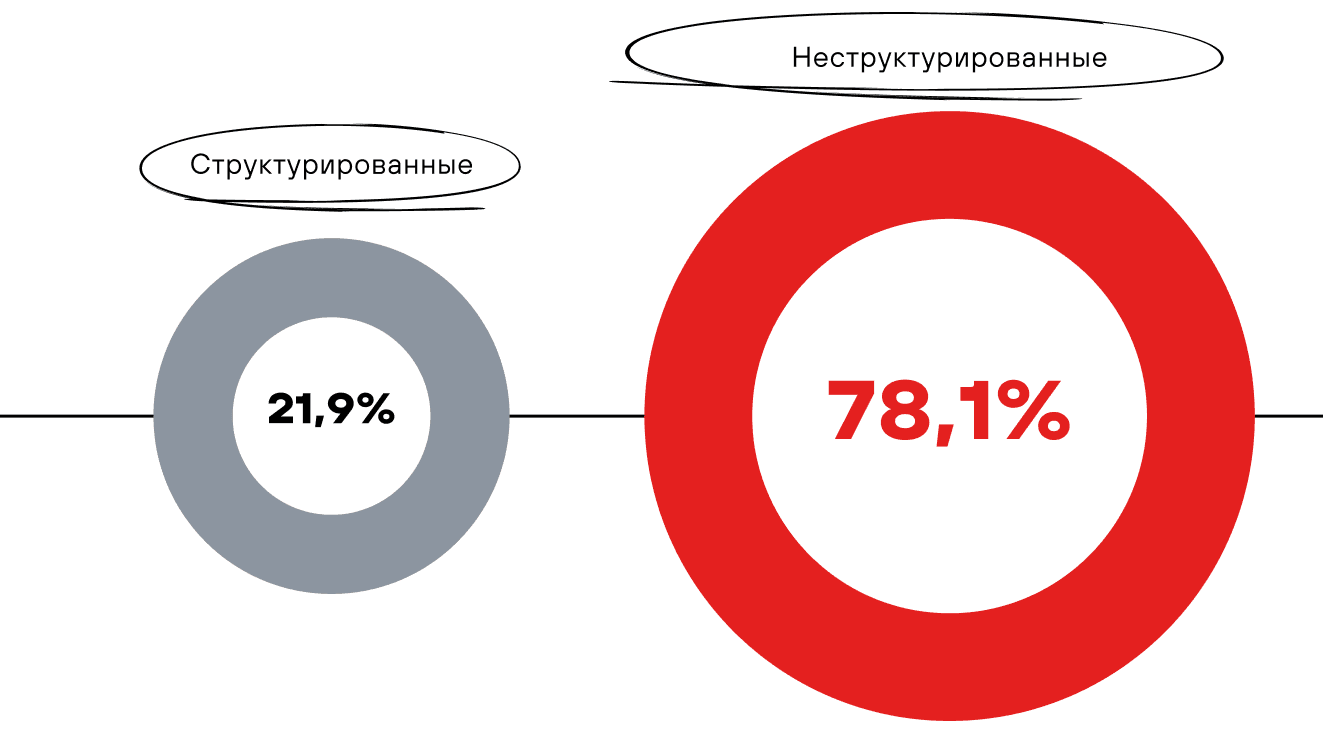
На текущей стадии развития продукта мы сфокусировались на работе с текстовыми данными (это самый распространенный тип информации) и выделили два формата их представления:
- структурированные данные — организованные в виде таблиц;
- неструктурированные данные — документы, переписки, логи, отчеты и др.
В рамках программы «Ранние ПТашки» мы изучили, как российские компании на самом деле хранят и используют информацию. Анализ показал, что структурированные данные — это не всегда реляционные БД. В некоторых случаях это могут быть полуструктурированные файлы .xlsx или .csv. Кроме того, в инфраструктурах часто встречаются атомарные БД, развернутые для решения конкретных задач: одни обслуживают самописные приложения заказчиков, другие — CRM-системы отделов, связанных с бухгалтерией, и т. д. Причем каждая из баз может состоять из десятков и даже сотен таблиц. Все это нужно учитывать при реализации механизмов классификации данных.
По итогам исследования мы сформулировали онтологию текстовых данных, в рамках которой PT Data Security должен в первую очередь покрывать два класса информации:
- персональные данные (ПДн) — любая информация, связанная с определенным или определяемым физическим лицом;
- информация об ИТ-ресурсах (IT Info) — данные об информационных системах, их конфигурациях, учетных записях и доступах к ним.
Почему регулярных выражений недостаточно?
Для начала мы проверили реальную эффективность регулярных выражений в части выявления чувствительной информации. Для тестов использовали ПДн: составили список сущностей (см. табл. 1) и подготовили отложенный набор размеченных данных с текстами на русском и английском языке. Итоговый датасет насчитывал свыше 3000 колонок (более 300 тыс. ячеек в совокупности).
| № | Сущности | Описание | Примеры |
|---|---|---|---|
| 1 | PERSON | Любая информация, позволяющая прямо или косвенно идентифицировать конкретного человека по имени или ФИО | Иван Иванов |
| 2 | DATE | Любые даты в различных форматах (день/месяц/год, месяц/день/год и т. п.), включающие календарные даты, даты рождения, даты транзакций и пр. | 12.05.2021 2021-05-12 |
| 3 | PHONE_NUMBER | Номера телефонов в национальном или международном форматах, включая коды стран и городов, с добавочным номером или без него | +7 (495) 123-45-67 8 800 555-35-35 |
| 4 | Электронные адреса в стандартном формате имени пользователя и домена (user@domain) | info@ptsecurity.com | |
| 5 | ORGANIZATION | Названия компаний, учреждений и организаций (государственных или коммерческих) | АО Позитив Текнолоджиз |
| 6 | IBAN | Международный номер банковского счета | DE89370400440532013000 |
| 7 | LICENSE_PLATE | Регистрационные номера транспортных средств | А123ВС 77 B202XT 98 |
Мы просканировали датасет тремя сторонними продуктами (коммерческими и open source): все они используют для поиска и классификации данных регулярные выражения и формальную экспертизу. При этом в каждом из этих решений применяется один или сразу два вида классификации: по содержимому и метаданным (наименования колонок).
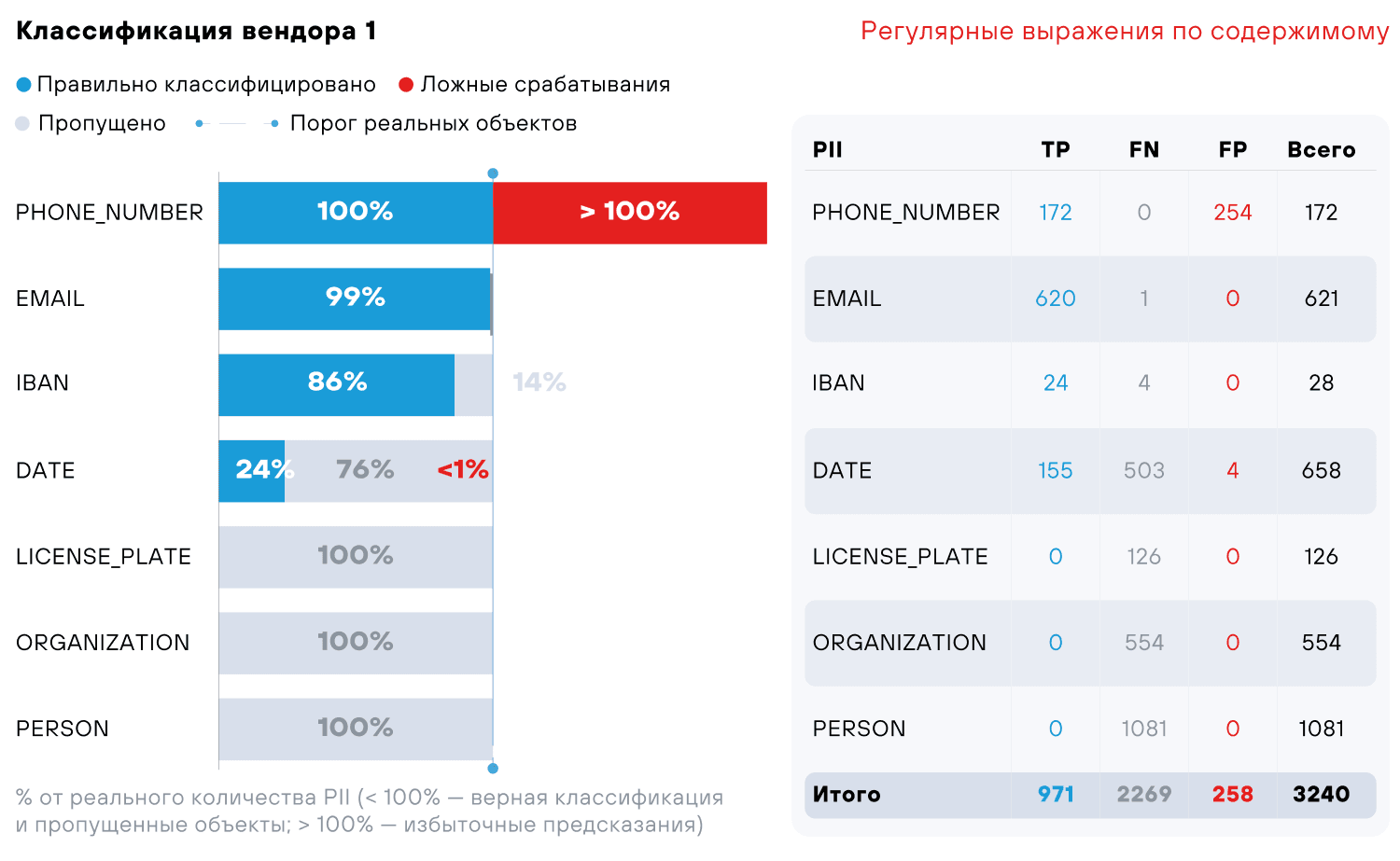
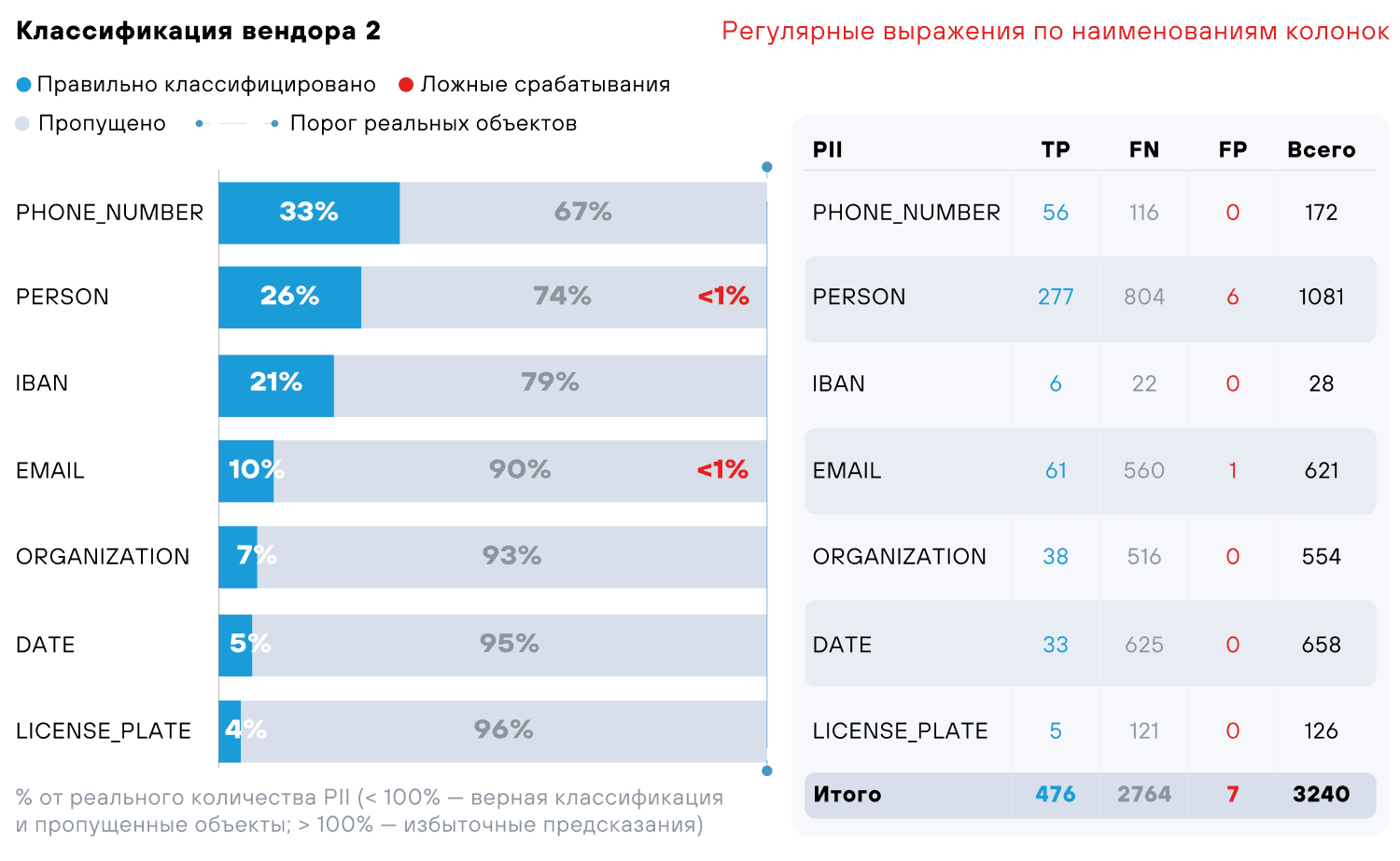
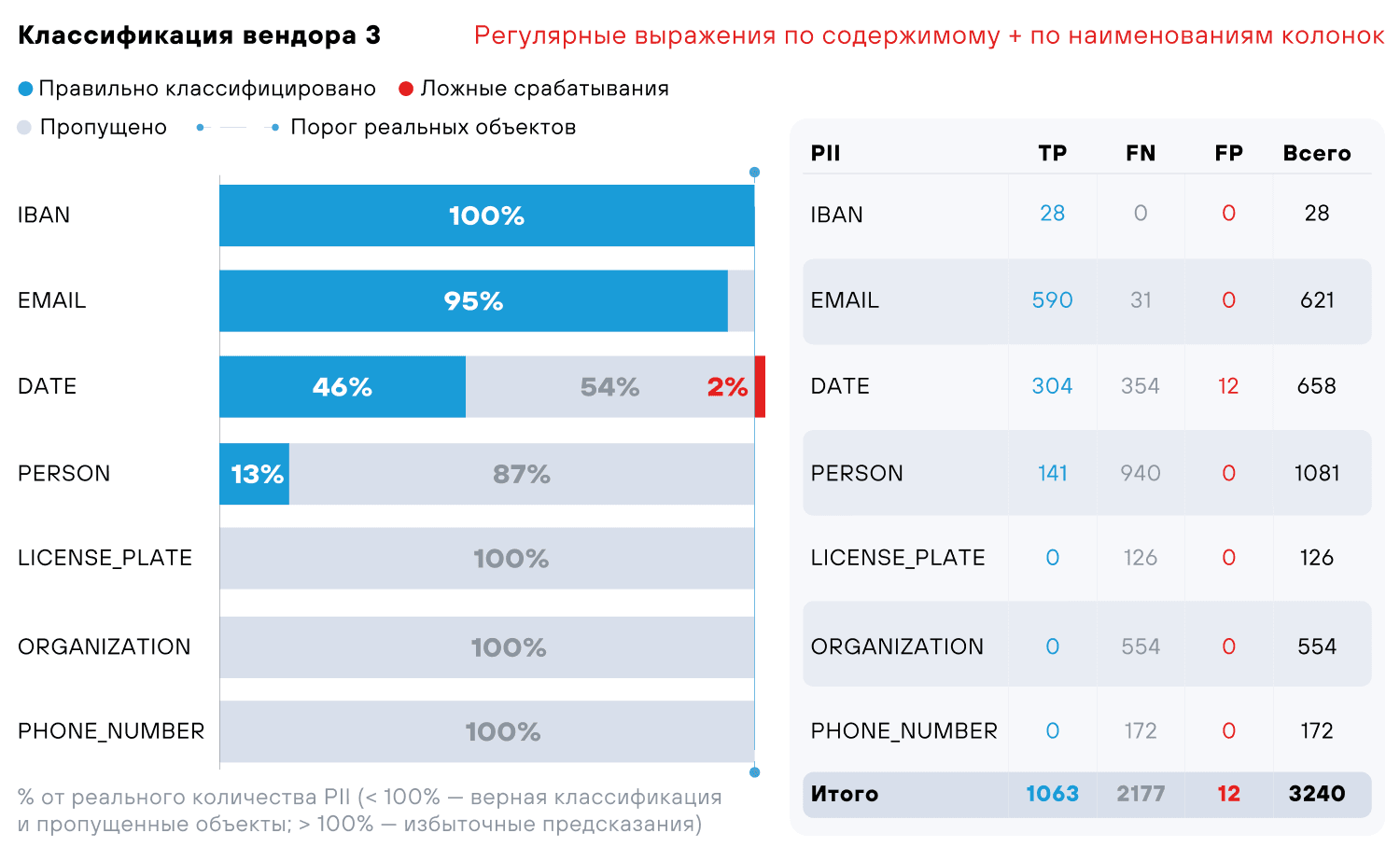
- PII — тип персональной информации (сущности из табл. 1)
- TP — True Positive (верно распознанные сущности)
- FN — False Negative (пропущенные сущности)
- FP — False Positive (ошибочно найденные сущности)
В рамках исследования мы отслеживали два показателя:
- recall (полнота) — сколько чувствительных данных обнаруживает система;
- precision (точность) — как редко система принимает безопасные данные за чувствительные и выдает ложные срабатывания.
При расчете метрик мы использовали макроусреднение (macro). Оно позволяет равномерно учитывать вклад каждого класса в общий результат и избежать смещения в сторону доминирующего класса. Результаты тестов представлены в табл. 2.
| macro-precision | macro-recall | macro-f1 | |
| Система 1 | 0,4827 | 0,4416 | 0,4110 |
| Система 2 | 0,9947 | 0,1504 | 0,2470 |
| Система 3 | 0,5660 | 0,3632 | 0,4042 |
Тесты показывают, что регулярные выражения успешно справляются только с сущностями EMAIL и IBAN, с остальными все не так гладко. С чем это связано:
- Ограниченная применимость шаблонов. Регулярные выражения не могут охватить все возможные вариации данных, особенно если речь идет о свободно записываемых сущностях (например, ФИО, названии организаций и пр.).
- Высокий риск ложных срабатываний. Случайные числовые последовательности могут быть ошибочно интерпретированы как номера телефонов (как у системы 1).
- Нестабильность в обработке редких и нестандартных форматов данных.
Резюмируем: регулярные выражения хороши для сущностей с четкими паттернами и низкой вариативностью. Любое отклонение от заранее заданного формата (например, пробелы в номере карты или необычное написание даты) приводит к пропуску данных.
Эксперименты с ML
Начнем с основных подходов, которые можно использовать при реализации ML-моделей для поиска и классификации ПДн.
CASSED
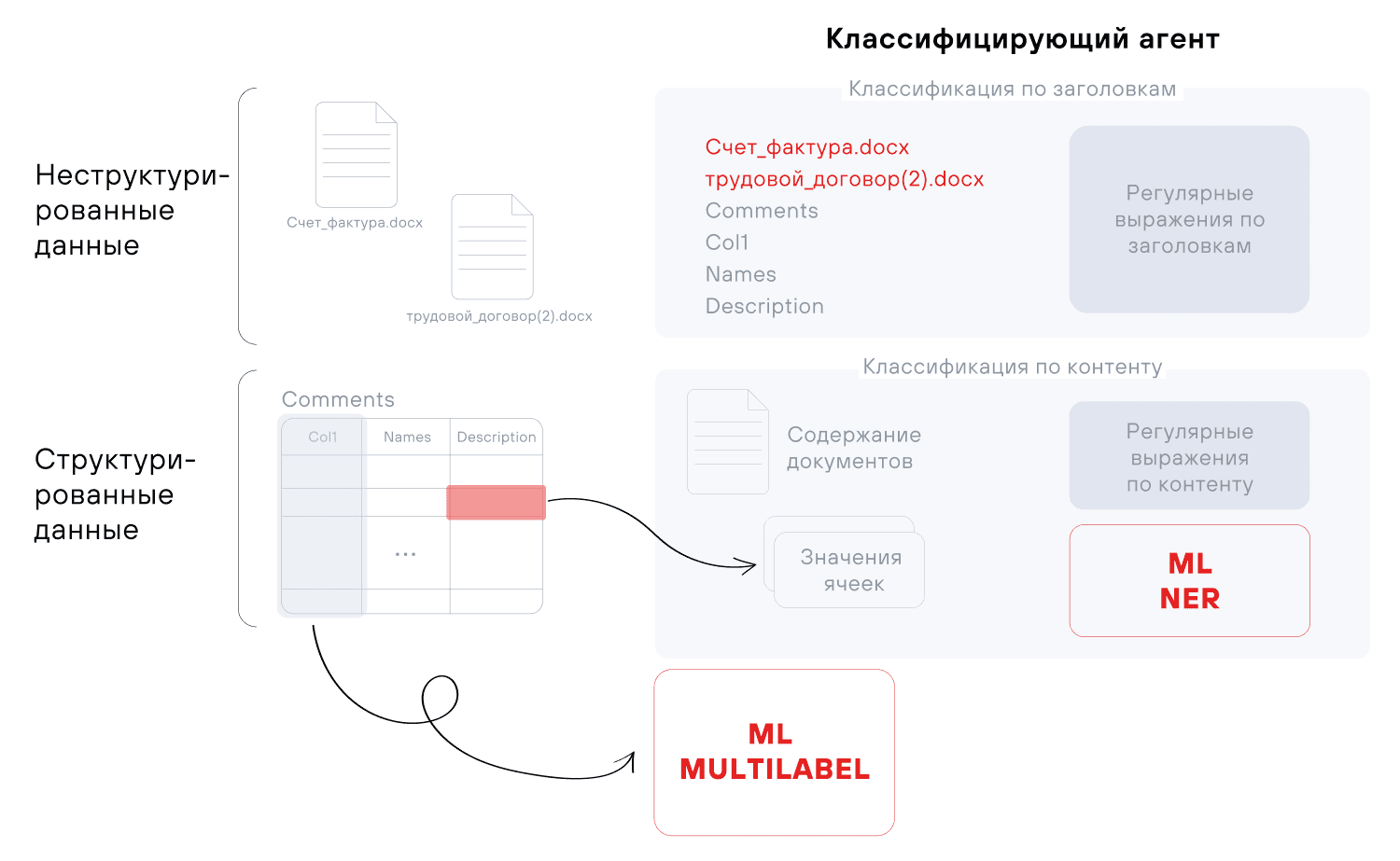
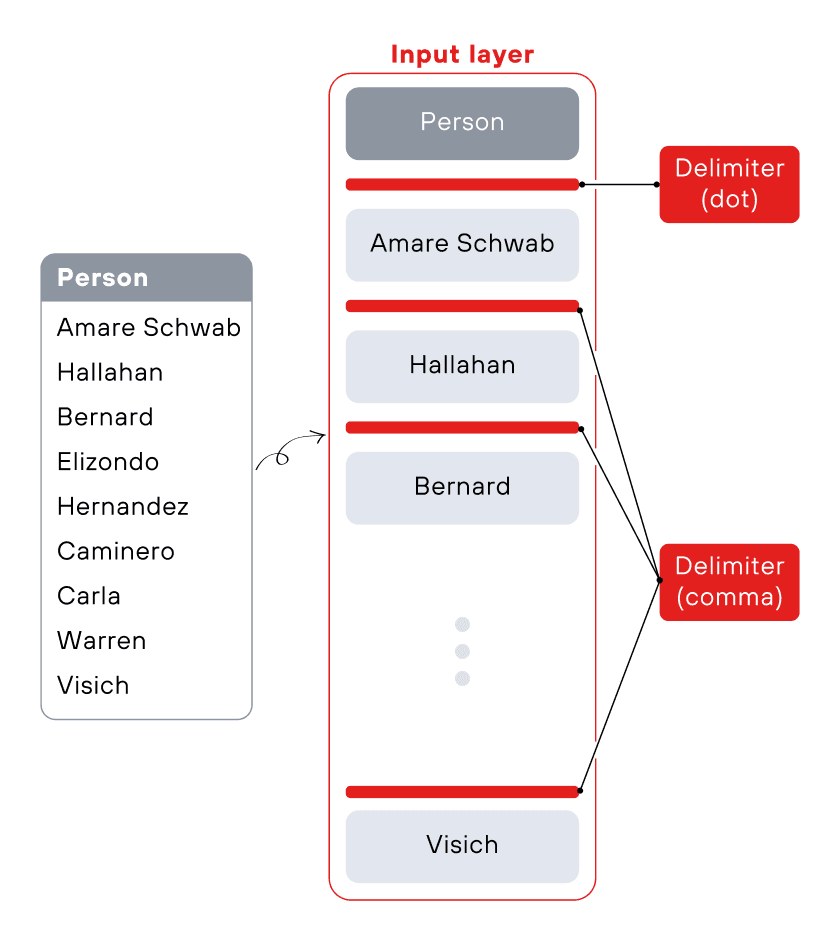
Для успешного обнаружения чувствительной информации в табличных данных важно не только корректно интерпретировать отдельные значения полей, но и учитывать контекст соседних ячеек (см. рис. 5). По сути, главная идея CASSED заключается в формировании контекста столбца: метаданные и значения ячеек объединяются в один вход для модели BERT (см. рис. 6). Это позволяет одновременно анализировать несколько ячеек одной колонки и присваивать ей одну или несколько сущностей. Таким образом, классификация становится более точной: помимо отдельных значений, мы учитываем их взаимосвязи и общую структуру данных.
Named Entity Recognition (NER)
Распознавание именованных сущностей — классическая задача в области естественного языка. Суть в том, чтобы находить и классифицировать отдельные фрагменты любых текстов. Проще говоря, метод NER можно применять и к структурированным, и к неструктурированным данным (см. рис. 5).
Сравнение ML-моделей
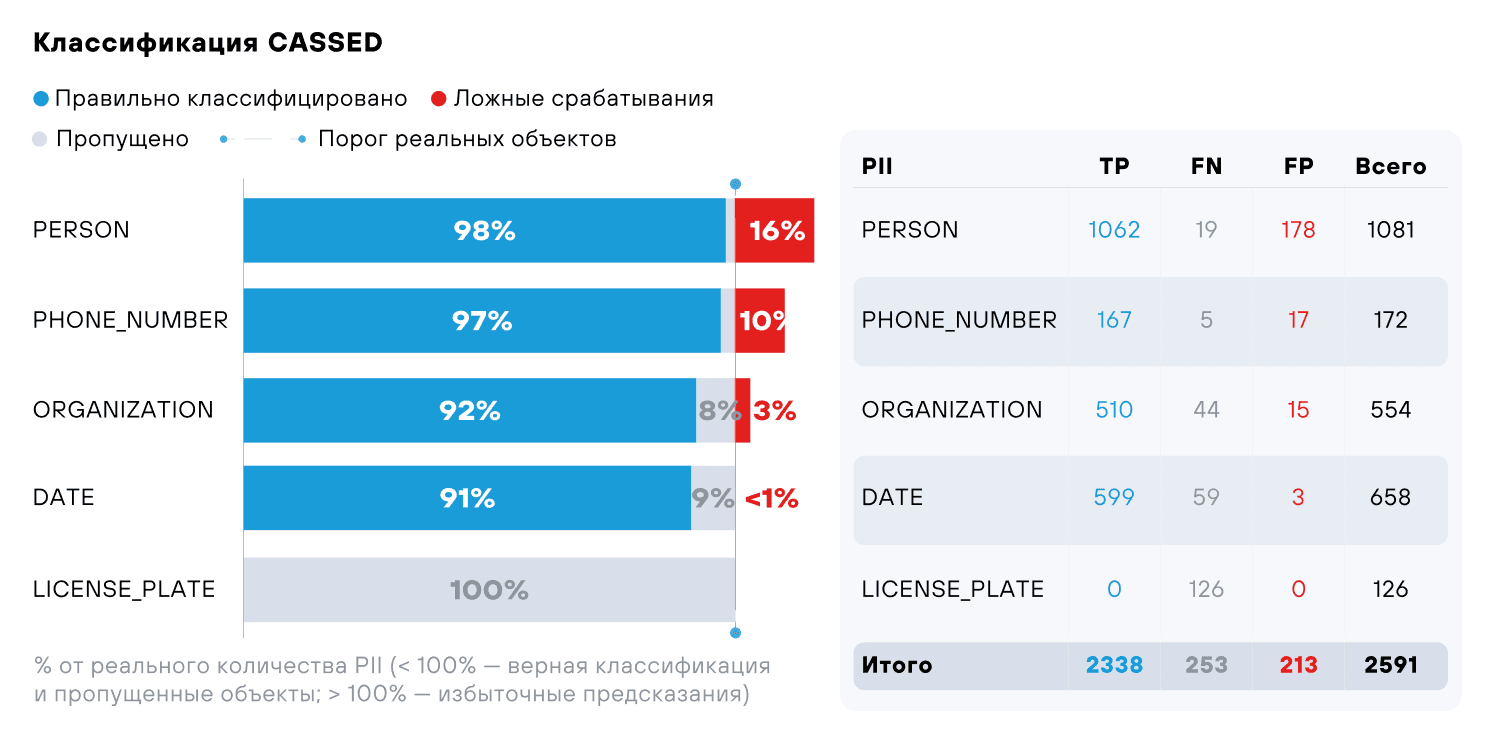
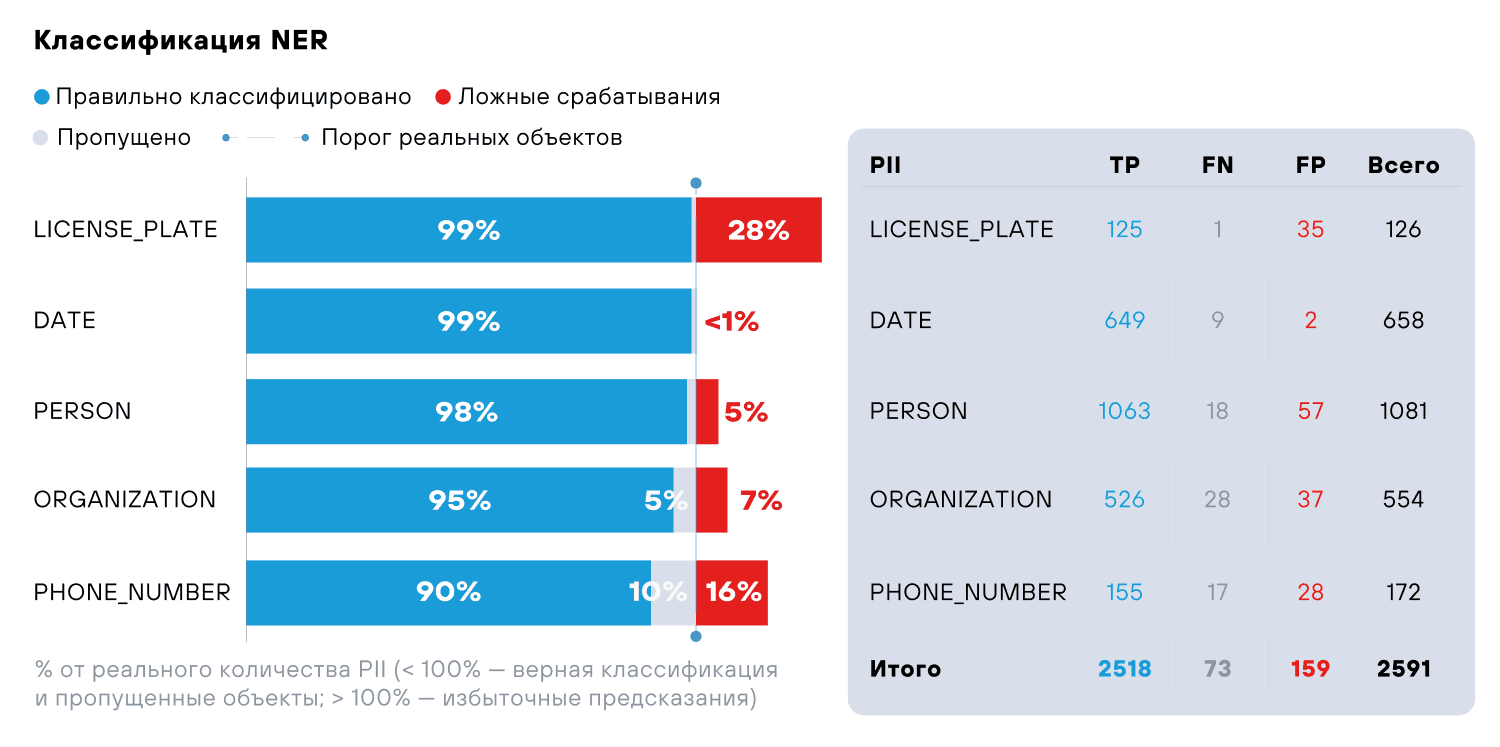
Мы сравнили эффективность CASSED- и NER-моделей на отложенном наборе данных, на котором ранее тестировали регулярные выражения (см. рис. 7–8). Отметим, что мы исключили из экспериментов сущности, которые успешно обрабатываются регулярными выражениями, и сосредоточились на оставшихся: `PERSON`, `PHONE_NUMBER`, `ORGANIZATION`, `DATE` и `LICENSE_PLATE`.
| ML/Metrics | macro-precision | macro-recall | macro-f1 |
| CASSED | 0,7461 | 0,7569 | 0,7499 |
| NER | 0,9017 | 0,9625 | 0,9293 |
Несмотря на то, что CASSED специально проектировался для определения чувствительных данных в БД, более универсальный NER отработал лучше. Кроме того, CASSED показал слабые результаты с данными на русском языке, что критично для PT Data Security и отечественного рынка в целом.
- CASSED подходит только для структурированных данных и не учитывает отдельные разнородные записи внутри одной таблицы. Среди плюсов метода можно отметить более высокую производительность, чем у NER.
- NER универсален, хорошо работает на русском и английском и требует меньше данных для обучения модели. Кроме того, метод позволяет выделять участки текста, содержащие чувствительную информацию (это можно использовать для внедрения в продукт функционала анонимизации).
Мы провели отдельные тесты, чтобы узнать, как CASSED и NER отрабатывают на неструктурированных столбцах (например, в датасете были сложные примеры json’ов). В итоге NER-модель показала уникальные детекты, а CASSED не обнаружил ни одного класса в тестовой подвыборке такого формата.
По итогам исследования мы решили внедрять в PT Data Security ML-модели на базе NER! Тем не менее исключать регулярные выражения из экспертизы продукта мы не планируем: они все еще остаются важной частью PT Data Security. Продукт использует оба подхода для достижения высокой точности классификации.
***
Напоследок обозначим ключевые векторы развития PT Data Security в части ML:
- Улучшение механизмов доставки экспертизы. Мы обнаружили, что анализ только первых или последних N записей столбца — не самый эффективный подход. Можно добиться большей точности, если модифицировать семплирование получаемых данных.
- Продолжение экспериментов с ПДн и расширение количества сущностей для данных IT Info.
- Разработка модуля для определения общего класса документа (финансовые, медицинские, юридические документы и др.) вместо обнаружения отдельных сущностей.




