О чем материал
Рассказываем о нашем подходе к оценке безопасности активов и периметра компании
Современные компании получают огромное количество данных о состоянии своей защищенности. Сканеры уязвимостей выдают сотни, а иногда и тысячи проблем, SIEM собирают миллионы событий в сутки, EDR фиксируют каждое движение в инфраструктуре. Но, несмотря на эту лавину информации, безопасники регулярно сталкиваются с одним и тем же вопросом от руководства: какой уровень защиты у нас сегодня? И ответить на него оказывается удивительно сложно…
Дело в том, что традиционные отчеты по уязвимостям (даже с цветовой маркировкой CVSS) не формируют целостную картину безопасности компании. Они показывают потенциально слабые места, но не отражают реальную способность СЗИ детектировать атаки и противостоять им. Более того, традиционная отчетность часто порождает «усталость от уязвимостей»: инженеры тонут в бесконечных списках CVE и не знают, за что браться в первую очередь.
Проблема усугубляется, когда речь заходит о внешнем периметре, где каждый открытый порт — потенциальная точка входа. Десятки защищенных серверов и хорошая статистика «в среднем по больнице» не спасут, если атакующие обнаружат всего один хост без патчей и мониторинга. Если он расположен в DMZ и имеет доступ к внутренним сетям, это может привести к компрометации всей инфраструктуры…
В результате возникает потребность в единой количественной и интерпретируемой метрике, которая:
- объединит данные из разных источников (уязвимости, логи, обновления);
- учтет не только вероятность подвергнуться атаке, но и способность ее обнаружить;
- позволит сравнивать состояния разных активов и периметров во времени;
- будет понятна и инженеру, и CISO, и даже нетехнарям.
Эта метрика не может быть абстрактной — она должна подсвечивать реальные проблемы инфраструктуры и напрямую коррелировать с реальными рисками: наличием эксплуатируемых трендовых уязвимостей, отсутствием логов EDR, использованием ОС без поддержки и т. д. Ее ключевая задача — помогать специалистам принимать решения: что патчить в первую очередь, какой актив изолировать, где усилить мониторинг.
Само собой, попытки количественно оценить безопасность предпринимались давно. Для этого применяются разные методы — от простых бинарных индикаторов («патч установлен / не установлен») до сложных risk-scoring-моделей на основе CVSS, EPSS и бизнес-контекста. Однако все эти подходы страдают от фундаментального недостатка: они оценивают уязвимость, а не защищенность инфраструктуры. То есть потенциальную слабость (например, в коде или конфигурации), а не способность СЗИ ее предотвратить, обнаружить или реагировать на эксплуатацию.
Сегодня мы представим свой подход к снаряду — практическую методику оценки защищенности, разработанную и апробированную в наших проектах по управлению внешней поверхностью атаки (Attack Surface Management) и MDR-мониторингу. Она позволяет превратить хаос данных в стройную систему, где каждый актив получает Score от 0,0 до 10,0, а за оценку всего периметра отвечает интегральный Perimeter Security Index (PSI). Мы уже используем эти наработки для приоритизации задач, обоснования инвестиций в ИБ и при подготовке к кибериспытаниям.
Три столпа оценки: логирование, патчинг, уязвимости
Анализ реальных инцидентов показывает, что успешная компрометация почти всегда связана со следующими факторами:
- Наличие уязвимостей, для которых есть публичные эксплойты.
- Отсутствие своевременного патчинга ОС, системного и прикладного ПО (особенно это касается установки критичных обновлений).
- Отсутствие или недостаточность логирования, что не позволяет детектировать атаку и реагировать на нее.
Именно эти факторы легли в основу нашей модели. По сути, наша методика количественной оценки защищенности активов строится на трех взаимодополняющих компонентах: способности системы детектировать, предотвращать и реагировать. Отмечу, что мы рассматриваем логирование не как «защиту», а как детектирующую способность (то есть компонент, без которого невозможно эффективное реагирование). В этом заключается принципиальное отличие нашего подхода от многих коммерческих сканеров, которые игнорируют наличие SIEM/EDR при расчете риска.
Логирование и мониторинг (вес 0,5)
Оценка логирования 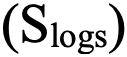 — это не просто проверка «есть/нет», а структурированный аудит источников данных, необходимых для детектирования инцидентов. Наша методика учитывает, что не все активы равнозначны, и подразумевает их разделение на два типа (чтобы избежать «размытия» требований»):
— это не просто проверка «есть/нет», а структурированный аудит источников данных, необходимых для детектирования инцидентов. Наша методика учитывает, что не все активы равнозначны, и подразумевает их разделение на два типа (чтобы избежать «размытия» требований»):
- MDR-активы — стандартные хосты под управлением MDR-сервиса. Здесь проверяются два компонента: системные логи (Syslog/AuditD для Linux, WinEvent/Sysmon для Windows) и данные от EDR-агента (наличие событий за 24 часа и актуальность последнего аудита).
- ЦПК-активы, которые участвуют в процессах SOC заказчика. Это серверы, контроллеры домена, СУБД, сетевые устройства в DMZ. К ним требования строже: дополнительно проверяются наличие и работоспособность NAD, SIEM (факт включения актива в корреляционный движок) и антивируса (в том числе с актуальными базами и агентом).
Каждый параметр бинарен (1/0), но внутри компонентов используются внутренние веса. Например, для EDR 70% веса приходится на наличие логов, а 30% — на свежесть аудита.
Формула выглядит так:
- Для MDR:
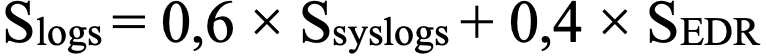
- Для ЦПК:
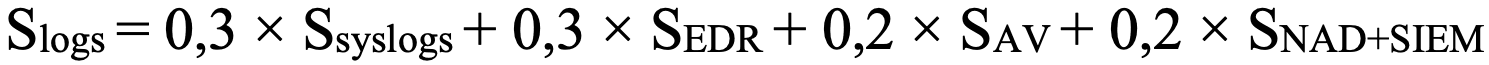
Этот подход гарантирует, что критический сервер без NAD или SIEM не получит высокий Score, даже если на нем установлен EDR.
Актуальность и обновления (вес 0,2)
Компонент  оценивает два простых, но критичных параметра:
оценивает два простых, но критичных параметра:
- Поддерживается ли ОС вендором (EOL/EOS → 0 баллов).
- Сколько времени прошло с момента последнего критического обновления безопасности (более 2 месяцев для Linux и Windows → снижение баллов).
Эта часть методики сознательно упрощена: вместо подсчета сотен CVE мы фокусируемся на своевременном патчинге как основном барьере против эксплуатации известных уязвимостей. Если организация регулярно устанавливает обновления, большинство RCE из топа угроз автоматически устраняются.
Наличие эксплуатируемых уязвимостей (вес 0,3)
Компонент 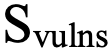 — самый чувствительный к реальным рискам. Он учитывает не все уязвимости, а только трендовые и реально эксплуатируемые. Они делятся на следующие категории:
— самый чувствительный к реальным рискам. Он учитывает не все уязвимости, а только трендовые и реально эксплуатируемые. Они делятся на следующие категории:
- R — RCE с публичным эксплойтом;
- L — LPE с публичным эксплойтом;
- D — DoS или нетипизированные уязвимости с публичным эксплойтом.
Для каждой категории задан вес риска: RCE — 0,8, LPE — 0,5, DoS — 0,2. Штрафы для системных и прикладных уязвимостей рассчитываются отдельно, с разным распределением весов в зависимости от типа актива:
- для серверов: 50/50% (ОС/ПО);
- для ПК: 65/35% (больший акцент на ОС);
- для сетевых устройств: только системные уязвимости.
Итоговая формула
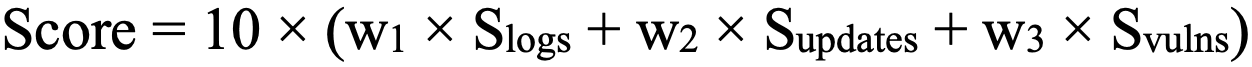
где:
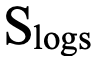 — нормированная оценка логирования (0–1);
— нормированная оценка логирования (0–1);
— оценка актуальности ОС и обновлений (0–1);
— оценка риска уязвимостей (0–1).
Веса:
 = 0,5 (логирование);
= 0,5 (логирование);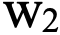 = 0,2 (обновления);
= 0,2 (обновления);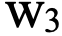 = 0,3 (уязвимости).
= 0,3 (уязвимости).
Таким образом, одна RCE снижает итоговый Score на 0,5 балла, а десять и более обнуляют компонент полностью. Этот подход делает методику устойчивой к шуму из незначимых уязвимостей, но при этом крайне чувствительной к реальным угрозам.
Почему логирование важнее уязвимостей
На первый взгляд, может показаться странным, что вес компонента логирования (0,5) выше, чем вес уязвимостей (0,3). Однако этот подход отражает реальность современных атак. Даже при наличии RCE злоумышленник не сможет долго оставаться незамеченным, если у вас настроен качественный мониторинг (EDR + SIEM + NAD). И напротив, отсутствие логов превращает любой актив в черный ящик: компрометация может длиться месяцами, как это было в случае с SolarWinds.
Можно сказать, что эти веса отражают не только саму возможность проведения атаки, но и стоимость ее последствий.
От актива к периметру
Оценка отдельных хостов — важный шаг, но этого недостаточно для эффективного управления безопасностью крупной инфраструктуры. Руководителю нужно понимать состояние всего внешнего периметра, а не только среднее значение для сотни серверов. Классический подход — использовать усредненный Score — опасен, потому что влечет за собой риск «замаскировать» один критически уязвимый актив за множеством хорошо защищенных. Поэтому мы ввели в методику Perimeter Security Index интегральную метрику, которая сохраняет чувствительность к подобным «темным пятнам».
Представим два сценария:
- 100 активов, у всех Score = 9,5 → среднее = 9,5.
- 100 активов, у 98 из них Score = 9,5, а у двух оставшихся Score = 1,5 и Score = 4,0 → среднее ≈ 9,3.
С точки зрения «классического среднего» разница минимальна. Однако во втором случае два актива практически готовы к компрометации, и именно через них злоумышленник может захватить инфраструктуру. Наша методика решает эту проблему с помощью простого, но эффективного механизма:
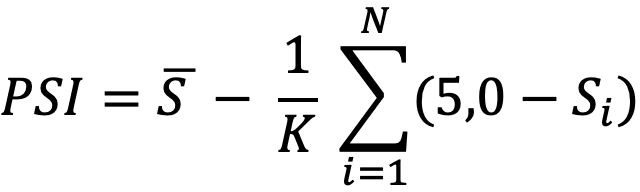
где:
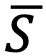 — среднеарифметический Score всех активов;
— среднеарифметический Score всех активов;- K — общее число активов в периметре;
- N — число активов с Score < 5,0;
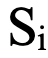 — Score
— Score 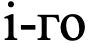 критического актива.
критического актива.
Каждый актив со Score ниже 5,0 штрафует общий индекс на разницу между 5,0 и его реальным значением. Штраф распределяется пропорционально размеру периметра (1/K), чтобы избежать чрезмерного влияния одного хоста в небольшой сети. При этом PSI не обнуляется, даже если есть один критический актив, — это сохраняет градацию и мотивацию к укреплению защиты.
| Сценарий | K | N | 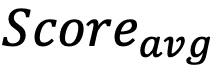 | 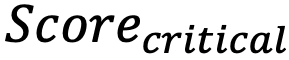 | PSI |
| 100 активов, средняя оценка — 9,5, критически низких оценок нет | 100 | 0 | 9,5 | ||
| 100 активов, средняя оценка — 9,5, критически низкая оценка у двух активов — 1,5 и 4,0 | 100 | 2 | 9,5 | 1,5 и 4,0 | 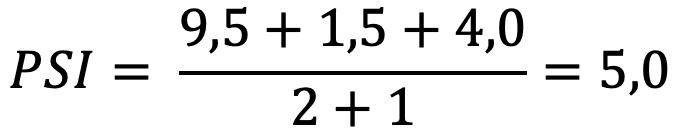 |
| 100 активов, средняя оценка — 9,0, критически низкая оценка у трех активов — 1,5, 2,0 и 2,7 | 100 | 3 | 9,0 | 1,5, 2,0 и 2,7 | 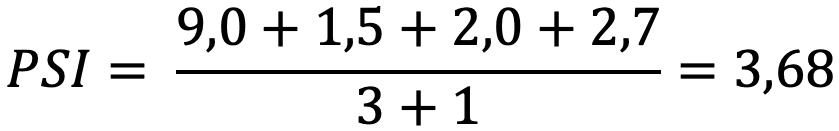 |
Отмечу, что порог 5,0 выбран не случайно. Согласно нашей шкале интерпретации, Score ≥ 5,0 — это пониженная, но управляемая защищенность, а Score < 5,0 — критическое значение, требующее принятия немедленных мер (изоляции, патчинга, аудита и др.)
Хотя базовая формула универсальна, ее все равно можно адаптировать. Например:
- Для DMZ или облачных периметров порог можно снизить до 6,0, потому что даже «удовлетворительной» защиты там будет недостаточно.
- Для внутренних сегментов можно повысить порог до 4,0, если они изолированы и не содержат критичных данных.
Но ключевой принцип остается неизменным: периметр настолько силен, насколько силен его самый слабый элемент. А PSI как раз и позволяет измерить эту силу.
***
Наша методика уже доказала свою эффективность. В MDR-сервисах — как инструмент для приоритизации инцидентов и выявления слепых зон мониторинга, а в SOC — как основа для автоматических алертов. Модель универсальна и подходит для:
- оценки зрелости периметра перед запуском MDR/ASM;
- мониторинга динамики безопасности во времени (например, PSI до и после кампании патчинга);
- сравнения разных площадок или бизнес-единиц;
- подготовки к регуляторным проверкам, где требуются доказательства управляемости рисков.
Мы не претендуем на «единственно верный подход», но предлагаем рабочий инструмент, который помогает ИБ-командам говорить с бизнесом на одном языке, принимать решения на основе измеряемых данных и, главное, отслеживать прогресс в укреплении безопасности компании.



