О чем материал?
Разбираемся, как архитектура lakehouse меняет привычные механизмы работы SOC и позволяет выявлять атаки, для которых еще нет названия, отчета и TTP
Про lakehouse в SOC обычно говорят следующее: большие объемы данных, дешевое хранение, масштабирование и SQL поверх всего. Эти характеристики важны, но они описывают инфраструктуру и почти ничего не говорят о главном — способности SOC обнаруживать атаки. Так какие новые возможности дает нам lakehouse, чего не могут привычные инструменты?
Я использую термин lakehouse, потому что мы говорим не просто о хранении сырых данных, а о платформе, которая сочетает гибкость data lake с надежностью и аналитическими возможностями data warehouse. То есть данные в lakehouse сразу готовы для формирования аналитики и решения ML-задач.
Данные первичны
Исторически разработка правил обнаружения развивается реактивно: сначала атака, затем отчет (разбор, TTP, инструменты) и только после этого детект. Практическая реализация выглядит примерно так:
- сигнатуры и регулярные выражения, которые ищут конкретный артефакт;
- простые корреляции событий по времени и ключам;
- пороговые правила: «если больше N за T».
Эта модель логична и до сих пор хорошо работает против известных техник. Большая часть сигнатурных правил, корреляций и порогов — это формализованный опыт прошлых инцидентов. Однако у такого подхода есть естественное ограничение: обнаружение неизбежно запаздывает относительно реальности. В результате SOC становится системой воспроизведения уже описанных атак, а не инструментом для исследования происходящего в инфраструктуре. Новое поведение может быть замечено только после того, как получит название, описание и правило.
Архитектура lakehouse, в свою очередь, смещает фокус с самой атаки (как объекта обнаружения) на изменение состояния инфраструктуры. Здесь первичны данные, что позволяет формулировать детекты в виде аналитических гипотез: «Как изменилось поведение объекта относительно его же прошлого?» или «Чем этот объект отличается от тысяч аналогичных?». При этом аналитический запрос может одновременно опираться на текущее поведение объекта и на его же историческую норму. Это позволяет сравнивать действие не с абстрактным правилом, а с тем, как этот субъект вел себя раньше. История в lakehouse становится частью детекта.
Для этого используются сложные SQL‑запросы, многомерные JOIN’ы, оконные функции и агрегаты по времени. Там, где это оправданно, поверх данных строятся ML‑пайплайны: обучение, валидация, переобучение — без копирования в отдельные среды. Но инструменты здесь вторичны: SQL, Spark и Python — это всего лишь способы задать вопрос. Важны сами данные и возможность работать с ними целостно.
Как строятся гипотезы в lakehouse
Как и в классической схеме, в lakehouse разработка детекта начинается с гипотезы: например, «Злоумышленники используют для закрепления службы Windows». Это распространенный прием как в ручных атаках, так и во многих инструментах постэксплуатации (от PsExec-подобных техник до фреймворков уровня Cobalt Strike). В сигнатурной модели следующим шагом обычно становится поиск характерных параметров создания сервисов. Этот подход эффективен, когда мы знаем, что нужно искать, но он плохо работает против вариаций и новых реализаций известных инструментов и техник.
При наличии исторических данных гипотезу можно сформулировать иначе. Вместо «Какой инструмент используют атакующие?» — «Какое поведение выглядит нетипично?». В этом случае аналитик отталкивается не от индикаторов, а от изменений состояния системы. Например, можно задать простой вопрос: «Какие службы Windows появились сегодня, но ранее не встречались в инфраструктуре?». Если процедура не имеет сигнатур, при таком подходе она все равно проявится как отклонение.
В качестве примера рассмотрим запрос (см. рис. 1):
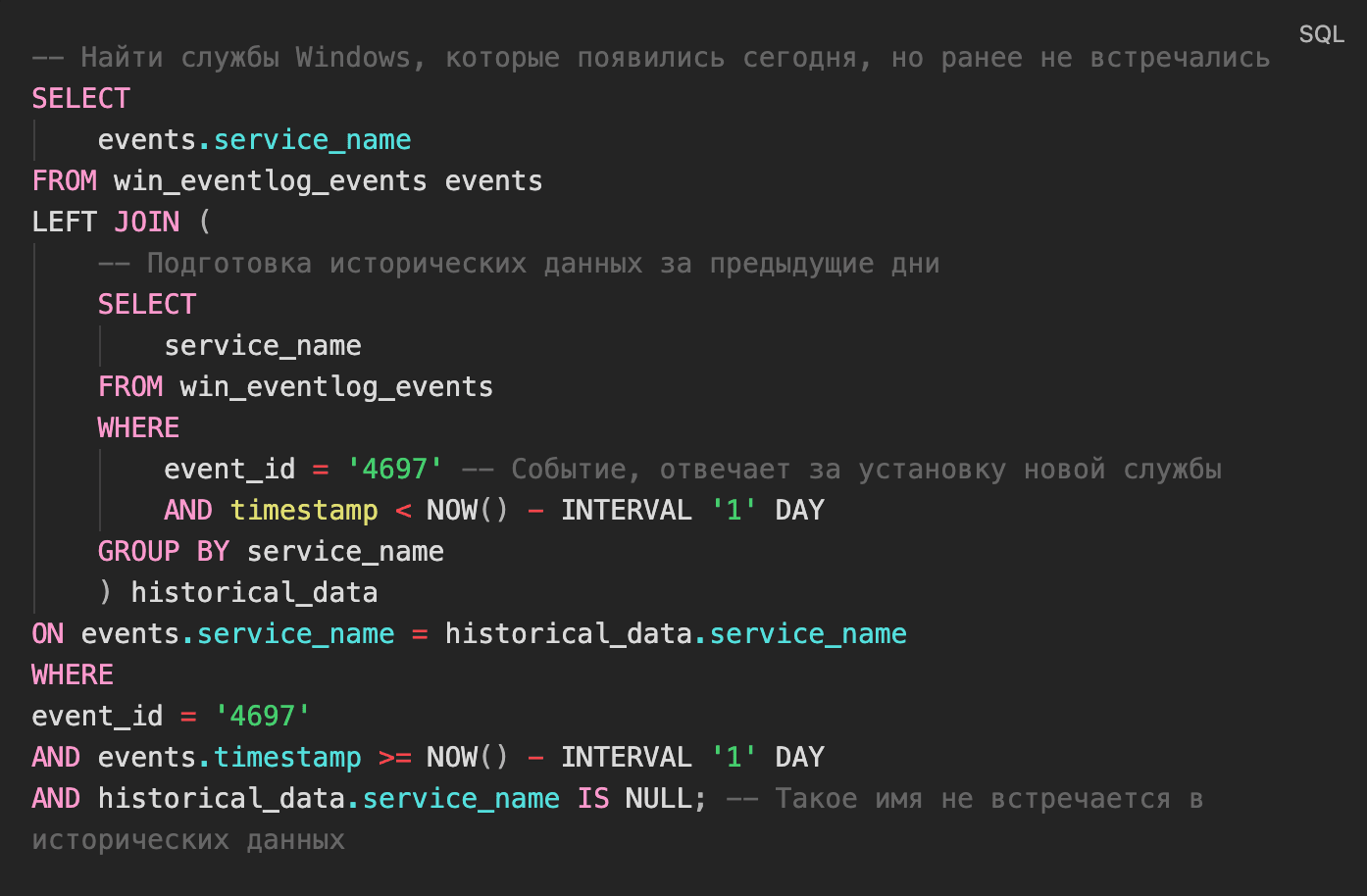
Приведенный выше запрос намеренно упрощен: он не учитывает user-mode-сервисы, где часть имени может быть случайно сгенерирована и потребует нормализации. В реальной практике такие случаи предварительно обрабатываются: выделяются стабильные части имени, используются регулярные выражения и группировка по шаблонам.
Историческую выборку также можно ограничить службами, которые наблюдались более чем на N узлах. Это уменьшает влияние редких, но легитимных сценариев и формирует более устойчивое представление о типовом поведении. Подобные запросы часто используют агрегации по множеству хостов, COUNT DISTINCT, а также оконные функции для анализа во времени и поиска всплесков.
JOIN позволяет добавить дополнительный контекст. Например, можно найти процесс-создатель сервиса, пользователя, хост и время жизни службы. В результате аналитик получает не просто список новых сервисов, а основу для быстрой оценки риска. Или основу для новых гипотез: «Найти процессы, которые раньше никогда не создавали службы, а сегодня создали» или «Найти процессы, которые создали нетипичные для себя службы».
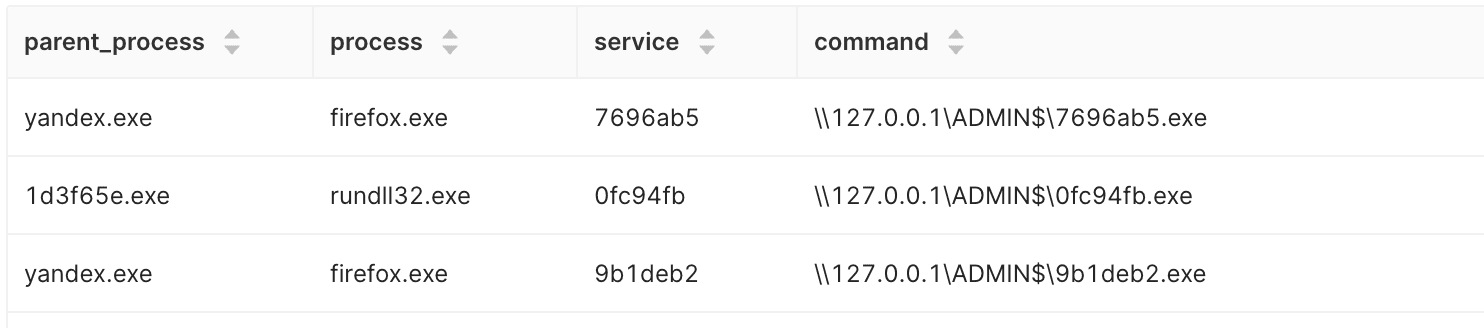
Подобный подход масштабируется лучше сигнатурных правил: он не требует обновления при появлении новых инструментов и устойчив к вариациям техник.
Из описания атаки детект превращается в проверку гипотезы о нарушении нормального поведения.
«Норма» как вычисляемая величина
В классических детектах «норма» зашита в голове автора правила и аналитиков. Именно поэтому любое правило со временем обрастает множеством исключений и десятками условий, которые отражают уже не поведение атакующих, а накопленный опыт ручной фильтрации. В результате борьба с False Positive (FP) быстро превращается из технической задачи в операционную. В крайнем случае правила вообще отключаются, алерты игнорируются, а общее доверие к детектам падает. По сути, SOC начинает оптимизироваться не под обнаружение атак, а для снижения нагрузки на аналитиков.
Но инфраструктура меняется, белые списки устаревают. В этой точке поиск новых угроз останавливается. Любой детект, который не имеет четкой сигнатуры и стабильного уровня шума, воспринимается как риск для эксплуатации. Важно понимать, что это не проблема качества правил или компетенций команды. Это следствие подхода, в котором «норма» — не объект данных (то есть ее нельзя вычислить).
В lakehouse норма не задается вручную, а вычисляется на основе исторических данных, из реального поведения инфраструктуры. Это снижает количество FP без ручного обновления белых списков и позволяет сделать детекты устойчивыми к изменениям инфраструктуры. Вместо 20 исключений в правиле мы сравниваем поведение процесса с его же историей и сразу отсеиваем типовую активность. Если исполняемый файл месяцами запускается с одними аргументами, взаимодействует с фиксированным набором доменов и ведет себя одинаково на сотнях узлов, система узнаёт его как часть фона.
Единое аналитическое пространство
Если отбросить инструменты и маркетинг, классический SOC живет по простой модели: СЗИ регистрируют алерты, затем проводится анализ и расследование. EDR, NDR, TI feeds решают свои задачи и выдают вердикт: алерты сходятся в SIEM или SOAR. Далее идут процедура обогащения и верхнеуровневые корреляции, которые связывают алерты и сигналы между собой, чтобы повысить надежность срабатываний, и добавляют к ним контекст из других источников. Это действительно помогает принимать решения. Но сам контекст все равно остается фрагментарным: обогащение усиливает известные детекты, но почти не помогает обнаруживать новое. В этой парадигме задать детект, выходящий за логику работу конкретного СЗИ, практически невозможно: требуется дублирование данных.
Lakehouse меняет не инструмент, а точку отсчета: сначала все сырые данные оказываются в одном аналитическом пространстве (с сохранением истории и связности), а только потом поверх них формулируется логика обнаружения. Благодаря этому контекст (история действий, окружение, роль, бизнес-процесс) по умолчанию становится частью детекта, то есть мы собираем и связываем сигналы без предварительной оценки их важности. К примеру, новый объект, который сразу начинает активно взаимодействовать с сетью, выделится на фоне остальных даже без наличия соответствующей сигнатуры.
Важно отметить, что lakehouse не дает преимуществ в сценариях, где требуется мгновенная реакция на хорошо формализованные события. Детекты уровня «произошло X → сработал алерт» по-прежнему эффективнее реализуются в классических real-time-системах. Lakehouse же полезен в аналитических сценариях, в которых ключевую роль играют контекст, история и полнота данных.
Другим немаловажным моментом остается общая зрелость SOC: качество источников, стабильность схем и выстроенные процессы управления данными. Без всего этого lakehouse остается мощным хранилищем, но не становится основой для устойчивого обнаружения.
Как это работает
Рассмотрим пример с поиском туннелей и скрытых каналов управления. Их нельзя обнаружить только с помощью SIEM или NTA, по крайней мере с достаточной надежностью. Журналы ОС содержат информацию о процессе и его контексте, когда тот открывает сетевое соединение. Но что происходит в трафике, остается невидимым. NTA же, наоборот, видит полный трафик, разбирает протокол со всеми заголовками, но ничего не знает о процессе, породившем этот трафик.
При горизонтальном перемещении туннель станет порождать NTLM-трафик, так как атакующий будет использовать украденные учетные данные для авторизации на других узлах. Поэтому использование NTLM-аутентификации может быть индикатором горизонтального перемещения через оставленный туннель. При этом трафик будет выглядеть легитимно.
Вместо поиска конкретных инструментов мы будем искать процессы, которые используют NTLM нетипичным образом. Обычно NTLM-запросы инициируются вполне предсказуемыми компонентами: например, системными службами Windows, проводником, службами файлового доступа или конкретными серверными ролями. Их поведение, частота обращений и направления аутентификации относительно стабильны и понятны. Если же NTLM-аутентификацию внезапно инициирует процесс, который обычно не работает с сетевыми ресурсами (например, пользовательское приложение, офисный софт или вспомогательная утилита), это может означать следующее:
- в памяти процесса выполняется вредоносная нагрузка;
- процесс используется как прокси для передачи аутентификационных данных через созданный атакующими туннель;
- происходит попытка relay-атаки.
Анализ выполняется в несколько этапов. Сначала объединяем телеметрию с хостов и трафик, чтобы сопоставить процессы с фактами аутентификации — JOIN между данными EDR, логами аутентификации и сетевой телеметрией.
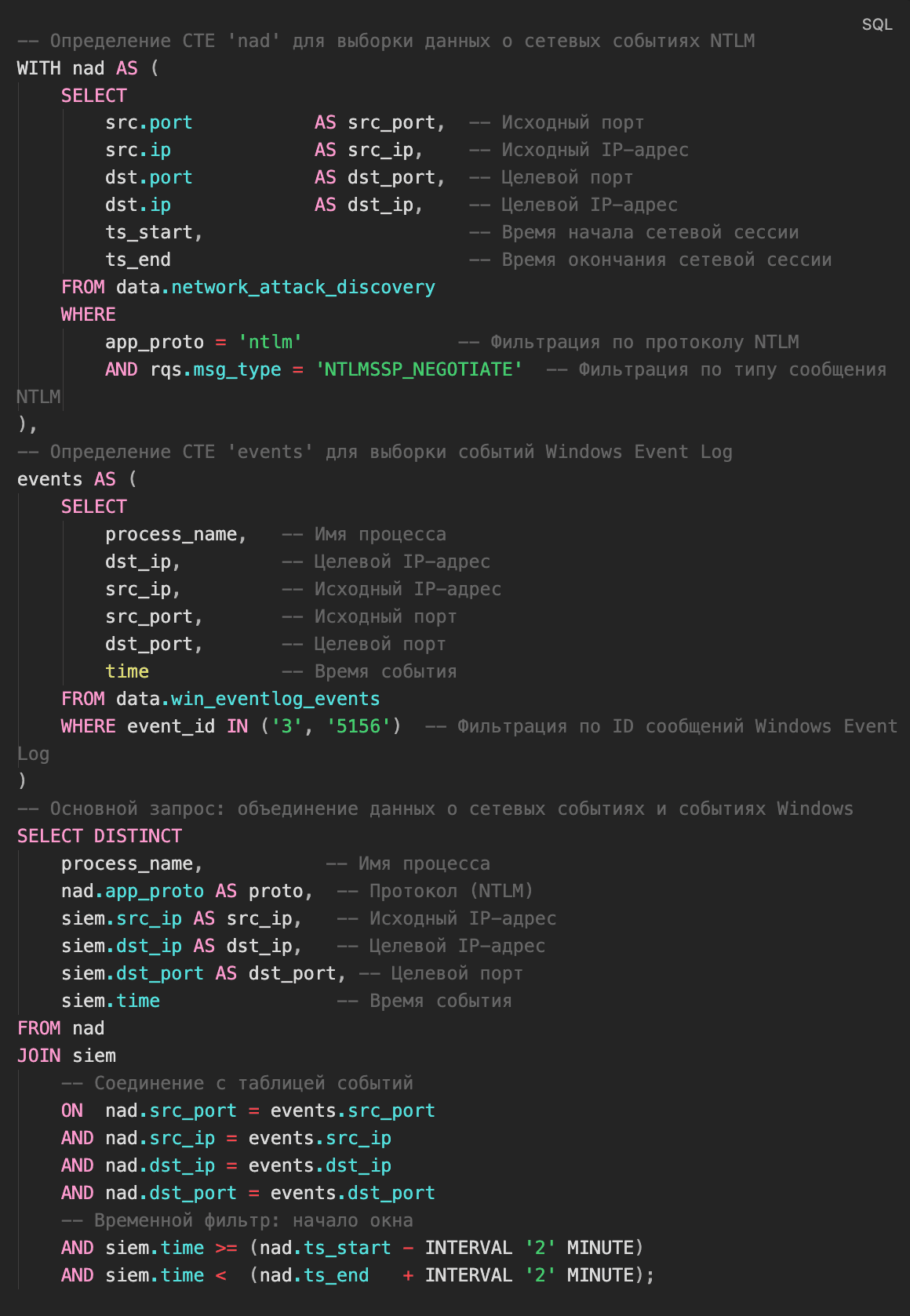
На этом этапе формируется базовое соответствие: «процесс — тип аутентификации — контекст». Затем текущие данные сравниваются с историческими — для выявления процессов, которые раньше не использовали NTLM (или делали это иначе).
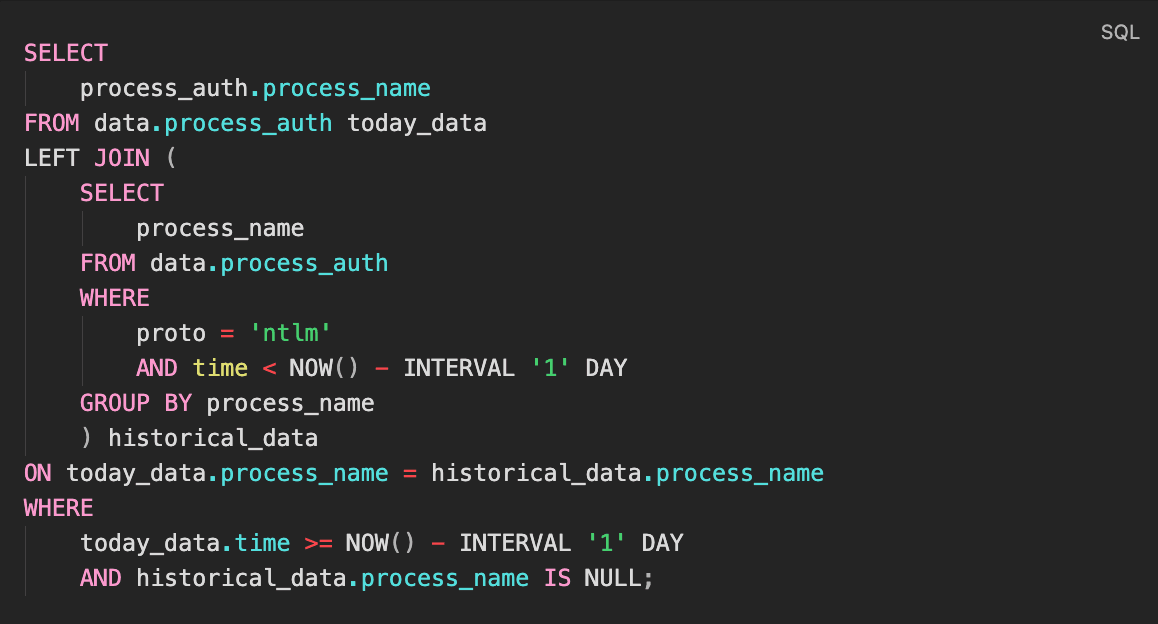
На практике такие задачи опираются на временные агрегации, оконные функции и подсчет частоты использования протоколов по каждому процессу. Это позволяет отличать устойчивые модели поведения от разовых отклонений. Именно эти отклонения, а не сам факт использования NTLM, становятся индикаторами скрытого канала управления.
Отмечу, что этот подход можно перенести на другие протоколы и свойства: DNS, Kerberos, SMB, особенности сетевых соединений или модели запуска процессов. В традиционной схеме подобный анализ зачастую невозможен из-за низкой глубины хранения и разрозненности хранилищ. Ключевые условия его проведения — это доступность истории, контекста и сырых событий в одном аналитическом слое.
Lakehouse + ML
Машинное обучение и поведенческие модели давно используются в SOC для поиска неочевидных связей, выявления аномалий и сокращения ложных срабатываний. Но большинство ML-инициатив сталкиваются с отсутствием данных нужного качества и глубины. Ограниченная история, предварительная агрегация и разрозненность источников приводят к тому, что модели быстро деградируют либо остаются экспериментальными.
Роль lakehouse — создать условия, при которых ML становится практичным и устойчивым элементом обнаружения. Исторические данные позволяют эффективно переобучать модели, проверять гипотезы и верифицировать результаты в контексте реального поведения инфраструктуры. В такой архитектуре ML используется там, где действительно дает преимущество: для выявления слабых сигналов, редких комбинаций признаков и отклонений, которые сложно или нецелесообразно формализовать правилами.
***
При наличии зрелых данных и процессов, lakehouse расширяет архитектуру SOC и добавляет системную возможность работать с поведением, историей и контекстом. Это позволяет дополнять реактивные сценарии обнаружения анализом изменений и аномалий, которые раньше было трудно или невозможно заметить, и постепенно смещать фокус SOC от воспроизведения известных атак к выявлению нового поведения инфраструктуры.
Именно здесь замыкается ключевая цепочка: SOC получает возможность выявлять атаки, для которых еще нет названия, отчета и TTP.



