О чем материал
Рассказываем о скрипте MP Events Monitor для комплексного анализа состояния источников событий в MaxPatrol SIEM и аудита активов в MaxPatrol VM. Скрипт позволяет проверять соответствие активов политикам сбора событий, выявлять проблемы с аудитом и мониторингом, а также генерировать детальные отчеты в Excel.
Самое страшное событие в жизни любого эксперта — внедрение продукта в реальную инфраструктуру. Это своего рода выживание в дикой природе. Первая робкая надежда в подобной ситуации — что клиент хорошо знает ИТ-ландшафт своей компании: какие в нем есть домены, устройства, как они связаны и т. п. Иногда дело даже доходит до уверенности, что клиент самостоятельно настроит аудит, подключит события, ну и вообще спасет себя сам. Как бы не так, на практике все куда прозаичнее… Заказчиком ИБ-проектов обычно выступает ИБ-подразделение компании, а вот руками (плюс хранителями знаний об инфраструктуре) — департамент информационных технологий. И это в лучшем случае! Бывает и так, что сведения «хранились на дне запертого шкафа в заколоченном кабинете», а тех, кто мог бы пролить на них хоть каплю света, в организации уже и в помине нет…
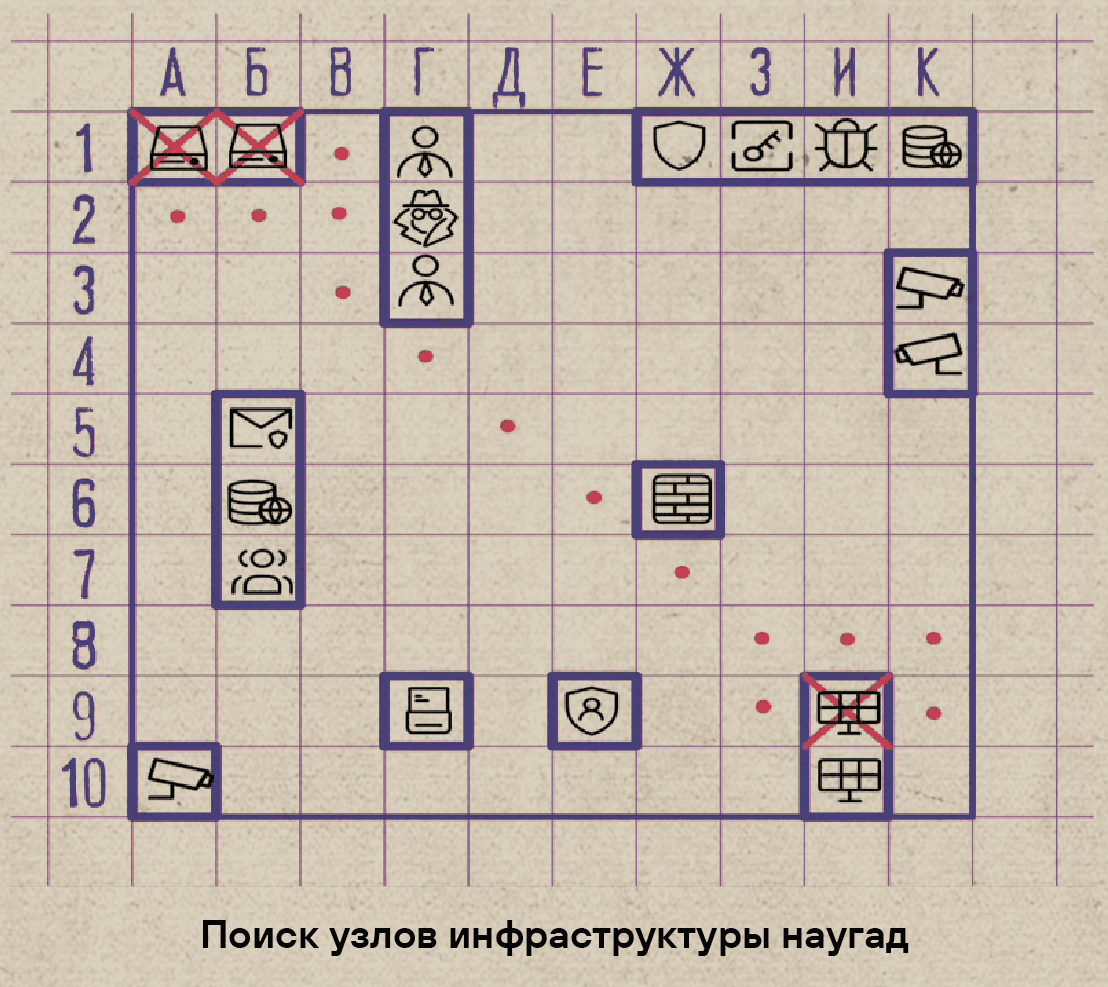
Таким образом, собирая разрозненные кусочки информации, слухи и корпоративные легенды о том, как функционирует инфраструктура, мы приходим к следующему: «Надеемся, что у нас шесть доменных контроллеров и два веб-сайта на периметре — вроде бы все». Реальность же вносит свои коррективы: доменных контроллеров оказывается восемь, причем у одного из них открыты порты для удаленного доступа, поэтому он виден всему интернету. А сайтов, впрочем, действительно два, но крутятся они на 50 виртуальных машинах, собранных в кластер, потому что «так архитектурно казалось правильно». И все это щедро приправлено незакрытыми уязвимостями, иллюзией контроля над происходящим и строгой уверенностью, что раз мы не видим хакера, то и он нас не увидит.

Ситуацию усложняет то, что системы мониторинга и сбора событий проектируются по принципу «Значимые узлы подключены, а неподключенные не требуют внимания». Эта позиция категорична, но с точки зрения логики работы продукта полностью обоснована: СЗИ ведь не принимают решений о важности узла, а просто защищают то, о чем знают.
Сегодня мы расскажем о нашем опыте решения подобных проблем, связанных с внедрением MaxPatrol SIEM и MaxPatrol VM в рамках одной платформы.
Внедряем комплекс продуктов Positive Technologies: что может пойти не так?
Первое же внедрение стало для нас жизненным уроком. Начнем с того, что в комплекс внедряемых решений в том числе входят:
- MaxPatrol SIEM. Позволяет собирать события безопасности с подконтрольных систем, проводить их анализ, коррелировать и выдавать сотрудникам SOC инциденты, на которые необходимо обратить внимание.
- MaxPatrol VM с технологией asset management (AM). Позволяет сканировать порты, находить интересующие системы, проводить их аудит и агрегировать полученные данные, чтобы оценить уровень покрытия, прозрачности и безопасности инфраструктуры.
- MaxPatrol EDR. Может проводить аудит систем, собирать события для SIEM, а также реагировать на злонаправленную деятельность — но только в пределах узла, на котором он установлен.
- Knowledge Base (PT KB — база знаний). Хранит знания о поддерживаемых событиях и правилах корреляции для MaxPatrol SIEM.
- PT Management and Configuration (PT MC). Обеспечивает единую среду для аутентификации пользователей, управления их учетными записями и интеграции наших продуктов.
В качестве пробы пера мы подготовили инструкцию для инженеров и внедренцев: когда и как сканировать в режиме HostDiscovery, в какой последовательности проводить аудит, как его читать, какие запросы использовать и главное — как интерпретировать полученные данные.
Со временем количество запросов росло, а наша скромная инструкция превратилась в объемное руководство, объединяющее порядка 60 сценариев. Каждый из них по-прежнему нужно было выполнять вручную с глубоким пониманием дела. Логика процесса, кратко сформулированная как «Scan → Analyze → Repeat», предполагала следующую цепочку действий: обнаруживаем новое корневое устройство — последовательно проверяем все дочерние узлы. Например, выявив сетевое оборудование с NAT-правилами, нужно немедленно сделать соответствующие запросы, чтобы убедиться, что все перечисленные в правилах устройства регулярно сканируются.
Однако при демонстрации подхода клиенту выяснилось, что он ждал от системы мониторинга прозрачного и автоматизированного процесса, а столкнулся с необходимостью постоянного ручного вмешательства. И даже возможность сохранения запросов не решила проблему: ручное управление отнимает время специалистов, а денег на отдельного сотрудника под эту задачу в бюджете SOC нет.
Стало очевидно, что наш подход нужно не просто оптимизировать, а кардинально переработать. Для автоматизации процесса необходимо было научиться отправлять в MaxPatrol VМ PDQL-запросы через API, структурировать данные и выводить их в унифицированном формате.

И снова проблема?
Для начала мы создали скрипт для MaxPatrol VM, который автоматизирует выполнение заранее прописанных запросов, сохраняет сырые данные в Excel и обрабатывает в отдельных отчетах. Это помогло сократить время на рутинные операции, но возникла новая проблема: даже автоматизированный аудит оставался статичным. Анализ показывал устаревшие или невыполненные проверки на отдельных узлах и в сегментах сети, но не отвечал на главный вопрос: какова реальная степень защищенности инфраструктуры? Ведь данные, собранные в прошлом, не отражают динамику угроз здесь и сейчас.
Что со всем этим делать? Тут на сцену выходит MaxPatrol SIEM, способный преобразовывать колоссальные потоки сырых данных в четкие выводы. Но что, если эти выводы будут построены на пустом месте? Существует масса вариантов, где что-то могло пойти не так: пропущенный аудит, узлы, с которых никогда не собирались события, неактуальная экспертиза или забытые после обновления правила. Причина может быть любой, но итог будет один: хакер останется незамеченным.
Таким образом, перед нами встали две новые задачи: освоить API MaxPatrol SIEM и создать для скрипта модуль, который будет подтверждать, что все нужные события с проверенных узлов попадают в корреляционные цепочки. Справиться с API было не так уж сложно: нужно было только собраться с духом и прочитать техническую документацию. А вот определение нужных событий превратилось в настоящий квест. Мы собрали все корреляционные фильтры из стандартной поставки, выделили используемые события, убрали дубли и оформили итоговый список. Но клиент, изучив результат, тут же задал вопрос: «Зачем нам событие 1644, если оно генерирует огромный объем EPS?» Ответ потребовал глубокого погружения: «Оно критично для обнаружения сканирования LDAP». Но как только один вопрос решался, появлялся следующий (например, про событие 4688 и т. д.).
Изначально идея скрипта звучала как «освобождение от постоянных консультаций с экспертом». На практике же потребовалась не просто доработка, а полная перезагрузка его логики: изменение архитектуры затронуло десятки зависимых функций внутри скрипта (к слову, сейчас в нем около 15 взаимосвязанных классов и 110+ функций — ООП как-никак ;) ).
Наконец, мы решили показать клиенту, какие корреляционные правила перестанут работать, если данные исчезнут. «Молодцы?» — спросите вы. Нет! Даже если событие технически задействовано в правилах, нет гарантии, что оно активно в конкретной инсталляции: правила могут быть отключены на уровне ядра или вообще не установлены.
Потребовалась новая интеграция: на этот раз с API PT KB — для проверки статуса правил в базе знаний (за подтверждение их актуальности отвечает интеграция с API SIEM). Каждый новый интерфейс добавлял сложности, но к этому моменту написание модулей уже не вызывало ужаса. Куда сложнее оказалось оформить результаты в Excel так, чтобы даже самый придирчивый читатель не захотел лично отыскать авторов скрипта, чтобы задать им пару вопросов о структуре отчета...

Настройка MP Events Monitor
Итак, спустя пару тысяч букв, можно обсудить наши текущие результаты. Мы назвали разработанный скрипт MP Events Monitor. Системное название (имя основного файла для запуска) — event_checker; внутреннее — Nomos (так называется репозиторий). И да, список фич уже в работе, мы не сидим на месте (нам дали поднимающиеся столы) и стоим за наш продукт :)
Для начала здравый смысл подсказывает прочитать README.md, где описана вся последовательность необходимых действий. Если у вас скрипт в формате .py-файлов, необходимо:
- Установить свежий Python 3.13.
- В командной строке перейти в директорию со скриптом.
- Установить зависимости из requirements.txt через pip.
- Скопировать файл configs/example.config.env с именем .config.env. Разместить его в папке configs и заменить в нем незакомментированные параметры на ваши.
- Запустить event_checker.py.
Если же у вас собранный бинарный файл event_checker.exe, то инструкция сокращается до пунктов 2, 4 и запуска event_checker.exe
Изначально мы занимались перекладыванием JSON’ов, но потом решили освоить «новые» технологии и перешли на Pydantic, который упростил настройку и позволил получить приятную глазу справку.
Рядом лежит example.config.env: создайте свой .config.env, указав адрес «MaxPatrol 10» и логин/пароль. Конечно, Pydantic разрешит передать данные через CLI, но помните, что пароли в логах — это примерно как ключи под ковриком. SOC обрадуется, а хакер — еще сильнее.... Используйте .env — безопасность не терпит публичности!
Теперь вернемся к методам аутентификации, которые есть в MaxPatrol SIEM и MaxPatrol VM:
- Pat-токен, который выписывается в PT MC. Доступен с версии 27.3 и является оптимальным вариантом при работе с API.
- Логин-пароль: аналогично тому, как работает браузер — через cookies.
- Логин-пароль ClientSecret (с версии 27.3 считается устаревшим методом). Его использование было признано небезопасным из-за избыточности прав доступа токена.
MP Events Monitor поддерживает три способа передачи параметров: через .env-файл, переменные окружения или прямой ввод в командной строке. Он автоматически проверяет, достаточно ли прав у вашей учетной записи или токена для выполнения выбранных операций. Подробные примеры настройки вы найдете в файле example.config.env или через команду --help, где расписаны все доступные опции. Отметим, что при использовании .env-файла пароли и токены не попадают в логи запуска, что исключает риск утечки через системные журналы.
Ключевой элемент гибкости — файл assets_filters.json, который управляет PDQL-запросами к активам и политикам сбора событий. В нем собраны все проверенные запросы (ранее включенные в документацию), причем каждый запрос снабжен поясняющим комментарием (также появится в итоговом Excel-отчете) и списком корреляционных правил, к которым он относится. Например, запрос для анализа NAT-правил снабжен примечанием «Проверка актуальности сканирования устройств за NAT», а также указанием на связанные правила вида «LDAP-сканирование» и «Аномалии в сетевом трафике».
Файл можно адаптировать под свои задачи: удалить неприменимые запросы, добавить новые или изменить политики. Если по одному из запросов не найдено активов, скрипт пропустит этот сегмент и не будет создавать пустой отчет. Внутри JSON-файла присутствуют встроенные подсказки, что упрощает правку даже для тех, кто впервые взаимодействует с конфигурацией.
Чтобы определить доступные политики сбора событий и их связку с новыми запросами к активам, изучите файл event_policies.json. В нем описаны все политики: уникальные имена для связи с группами активов из assets_filters, PDQL-фильтры для получения событий и имена корреляционных правил, которые привязаны к этим фильтрам. Правила синхронизированы с актуальной версией MaxPatrol SIEM, по запросу доступна версия под ваш релиз PT KB — для ускорения настройки все заскриптовано. При расширении политик сохраняйте структуру JSON: удаление обязательных полей или нарушение иерархии (например, размещение правил вне массива) приведет к ошибке валидации.
Запускаем скрипт
Переходим непосредственно к запуску MP Events Monitor:
- Сначала скрипт проверяет права токена (или УЗ), так как по умолчанию включена работа с PT KB, а у токена таких прав может не оказаться. После проверки либо продолжается выполнение скрипта, либо выводится уведомление о необходимости сделать выбор: обновить токен или выключить режим работы с базой знаний (-k False).
- MP Events Monitor обращается к PT KB и достает статусы всех правил корреляции, оценивая, насколько коробочная экспертиза в принципе установлена. Результат проверок — Excel-файл, а также JSON-файл, из которого скрипт будет забирать данные во время работы.
- Скрипт начинает работать с фильтрами по активам (asset_filters), последовательно перебирая блоки. В каждом из них выполняется PDQL-запрос к MaxPatrol VM: таким образом достаются активы, входящие в каждую из групп.
- Согласно указанным политикам сбора событий для данных активов, скрипт забирает события из MaxPatrol SIEM (работа идет в многопоточном режиме).
- Полученный результат анализируется и выводится в единый Excel-файл. Здесь данные о событиях объединяются с активами и анализируется статус каждого актива. Также в конце обработки происходит общая оценка покрытия по данному блоку.
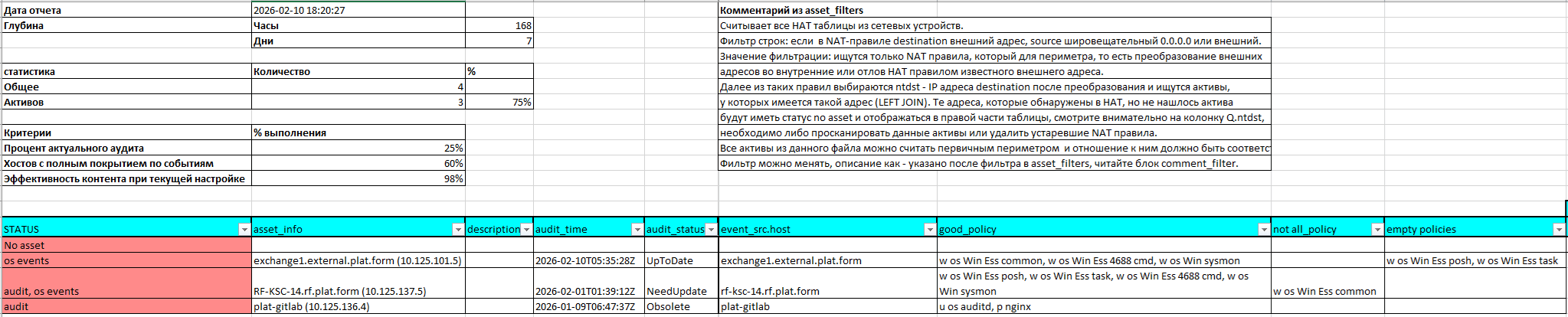
В примере на рис. 1 мы использовали результаты запроса NATed-узлов, которые собирали следующим образом: из активов сетевых устройств извлекались NAT-правила, где в поле destination указан внешний адрес, а в поле NormalizedTranslatedDestinationAddress — реальный внутренний (серый) адрес устройства, на которое перенаправляется трафик. Фактически с помощью этого запроса мы ищем первый шаг периметра, то есть узлы, доступные из внешней, неконтролируемой инфраструктуры.
В нашей лабораторной среде было обнаружено три подобных актива. Кроме того, одна из записей сигнализирует о наличии NAT-правила, для которого нет соответствующего актива — на это указывает строчка No asset. Причем ни одного актива со статусом ok обнаружено не было. Таким образом, один из узлов не отдает необходимые события, другой не был своевременно проаудирован, а на третьем присутствуют обе проблемы. Отметим, что к скрипту прикладывается описание, как читать отчеты, — смотрите в папку docs.
В нашем примере представлена только страница simple, которая отражает общее состояние инфраструктуры. Но доступны и другие страницы с более детальной информацией. Так, на странице FULL подробно описано все, что MaxPatrol VM возвращает в ответ на PDQL-запрос (см. рис. 2).

Для запроса по NAT-таблицам отображаются внешний и транслируемый адреса, а также транслируемые порты. Внимательный читатель может заметить, что в поле source стоит подсеть нашей лаборатории ;) Все последующие страницы в файле описывают политики событий, которые были проверены, то есть оказались применимы к данной группе узлов.

Откроем страницу «w os Win Ess common» — это политика, которая проверяет наличие базовых событий из журналов System и Security. Это наиболее характерные события, которые были отобраны методом экспертной оценки и поставлены на контроль (плюс на них базируется экспертиза).
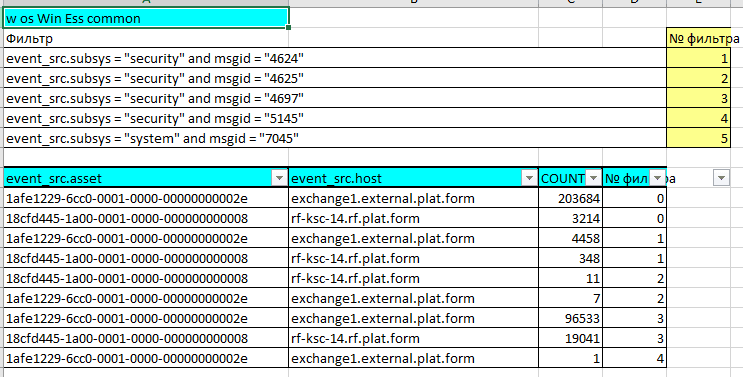
Для каждого узла выводится статистика: сколько событий и по какому фильтру за последние 14 дней было обнаружено в MaxPatrol SIEM. Ноль подсвечивается красным — это знак того, что сбор или журналирование событий данного типа на узле не настроены.

Схема по фильтру событий (в правой части отчета) показывает, какие правила применимы и каков их фактический статус для конкретной группы активов:
- Зеленый статус означает, что правило установлено и события для него есть. Можете не беспокоиться!
- Желтый показывает, что правило установлено, но необходимо либо добиться появления соответствующих событий, либо заполнить табличный список согласно документации пакета, к которому относится правило.
- Красный статус означает, что правило отсутствует в установочном наборе конвейера, а значит, его нужно туда добавить и установить.

Выделяем ключевые сегменты инфраструктуры
С техническими вопросами мы разобрались, пора переходить к концептуальным, а именно: какие сегменты инфраструктуры мы выделяем и почему?
В первую очередь мы стараемся очертить периметр организации, ведь именно туда постучится злоумышленник. Начинаем с проверки сетевых устройств. Сбор событий в этом случае не так важен: поток огромен, поэтому достоверный детект на таких данных все равно не построишь. Гораздо важнее заметить неотсканированный межсетевой экран (МСЭ). Причем запрос показывает производителя и модель устройства. Это критично, поскольку в схемах, которые вы получаете при внедрении, оборудование указывается именно так, а значит, можно сопоставить данные и понять, чего не хватает.
После анализа сетевых устройств анализируются NAT-правила МСЭ. Они позволяют переопределить внешний адрес во внутренний, то есть на хосте остается серый адрес, но сквозь МСЭ он становится доступен извне по белому адресу. В MaxPatrol VM отправляется запрос, который достает такие правила и ищет подходящие активы по серому адресу (NormalizedTranslatedDestinationAddress). Для этих активов проверяются сбор событий и валидность аудита.

В высоконагруженных веб-сервисах с распределенной архитектурой главный сервер редко указан в NAT-правилах: трафик проходит через каскад прокси (nginx, WAF, балансировщики). Мы как-то раз наблюдали в дикой природе следующий пример: NAT → nginx1 → nginx2 → PTAF → nginx2 → nginx3 → фронт (30 серверов). Причем лишние звенья (например, дублирующий nginx2) остаются без изменений — перенастройка подобных цепочек часто экономически невыгодна. Для анализа скрипт идентифицирует прокси-узлы, проверяет их аудит, а выходные серые адреса сверяет с активами, рекурсивно собирая всю цепочку. Каждый этап, от входящего NAT до финального фронта, автоматически оценивается на предмет актуальности сбора событий и покрытия правилами. Это позволяет выявлять слепые зоны даже в самых запутанных топологиях. Такой подход гарантирует: даже если в схеме есть избыточные элементы (как второй nginx2), их влияние на безопасность не останется незамеченным.
Сейчас MP Events Monitor поддерживает анализ nginx, HAProxy и PT AF, но при этом не различает, является ли прокси частью NAT-цепочки или же бэкенды доступны только внутри. Это ограничение возникло из-за глубокой вложенности запросов. В будущем мы планируем строить дерево топологии сопоставляя данные между этапами, чтобы точно определить, где заканчивается внешний периметр и начинается внутренняя сеть. Отдельно выделен поиск узлов с внешней адресацией через ACL: например, серверов, явно обозначенных как публичные, но защищенных правилами МСЭ вместо NAT. Ранее анализ ACL был отключен: запросы были слишком ресурсоемкими, а однозначно определить внешние правила не получалось. Если вы хотите увидеть всю модель доступа организации согласно ACL, используйте asset_filters_max.json.
После проведения анализа периметра скрипт переходит к внутренней инфраструктуре. Сначала идентифицируются доменные контроллеры (ДК): через сканирование стандартных портов для контроллера домена и данные MaxPatrol VM о роли DirectoryService. Если есть аудит по LDAP, запускается сканирование, которое выявляет не только доменные узлы, но и скрытые доверенные домены (как в случае с дочерней инфраструктурой, где забыли настроить сбор событий). Далее проверяются ключевые сервисы: MECM, Exchange, RDS, RDG, CS — для каждого в event_policies.json прописаны специфичные события.
Однако не все узлы входят в Active Directory: скрипт дополняет анализ проверкой автономных Windows-машин и UNIX-систем и выявляет слепые зоны. Например, тестовые серверы с открытыми RDP-портами или забытые виртуальные машины. Такой подход позволяет отследить путь атаки не только через веб-интерфейсы, но и через внутренние двери.
Отдельно остановимся на виртуализации, которая позволяет увидеть скрытую структуру распределенных систем. Например, в одном из проектов мы обнаружили 30 бэкенд-серверов за фронтендом путем анализа подсетей и иерархии виртуальных машин в единой папке гипервизора. А уже установленный у клиента PT NAD помог дополнительно выявить базы данных на физическом железе — по активным соединениям с уже известными узлами.
Для построения карты виртуальной инфраструктуры выявляются управляющие компоненты (VMware vCenter и Hyper-V) — через порты, установленное ПО и сетевые метки. Далее анализируются гипервизоры с привязкой к дата-центрам, чтобы понять физическое расположение ресурсов и выделить критичные сегменты. Виртуальные машины оцениваются в контексте этой структуры: например, серверы в изолированных дата-центрах помечаются как высокоприоритетные для аудита, а их статус проверяется через Excel-отчеты.
Кроме того, скрипт автоматически выделяет ключевые системы: после ServiceDiscovery ищутся GitLab (с runner-ами), JFrog Artifactory, OpenVPN, KSC и 1C с зависимыми серверами. Это позволяет быстро обнаружить уязвимые точки: например, забытые runner’ы GitLab с открытыми API или Artifactory без обновлений, которые хакер может использовать для захвата инфраструктуры.
Такой подход превращает сырые данные в целевые рекомендации: вместо «30 серверов за фронтендом» вы получаете «12 серверов в критичном дата-центре с просроченным аудитом, включая Artifactory».
***
Сейчас мы используем MP Events Monitor во всех внедрениях продуктов MaxPatrol SIEM и MaxPatrol VM, и это приносит свои плоды: верификация сбора и контроля покрытия заметно упростилась. Мы узнаем не обо всех победах, однако о самых эпичных случаях слухи доходят. Так, один из клиентов был уверен, что у него все настроено правильно — инфраструктура защищена. Но ради эксперимента все-таки разрешил нам запустить скрипт. Общая интегральная оценка показала менее 30% покрытия: клиент в срочном порядке пошел затыкать дыры с учетом полученных рекомендаций...
В заключение хочется сказать, что сейчас у нашего проекта 5230 строк кода. 140 841 символ (без учета табуляции и переходов на новую строку), 6 фича-реквестов и огромный потенциал. Будем рады фидбэку о его применении в ваших инфраструктурах!




